Avoimesta Ylen ja HS:n vaalikonedatasta löytyy hyviä analyysejä ja visualisointeja, esimerkiksi Juha Törmäsen analyysi ja visualisointi, Markku Niemivirran analyysit HS:n ja Ylen datasta ja näiden visualisointi (Taipale, Leinonen, Niemivirta). Latenttien komponettien mallinnuksesta kiinnostuneet voivat vilkaista myös Janne Sinkkosen latentin multinomiaalimallin koodia. Mallin tuottama grafiikka tuloksista Uudellemaalle kiinnostanee kaikkia.
Edellisissä on faktoroitu alkuperäisiä vastauksia ja ryhmitelty ehdokkaita; tehty siis varsinaista analyysiä vastausten taustalla olevista tekijöistä. Analyysit ovat oikein hyviä, joten kokeilen jotain muuta: luokittelijaa Ylen vaalikonedatalle. Luokittelija mittaa suoraan kuinka hyvin kysymykset erottelevat puolueita toisistaan ja kuinka todennäköinen ehdokas on kullekin puolueelle. Osaako kone erottaa puolueet toisistaan? Kuka on Ylen kysymysten perusteella kaikkein piraatein, kokoomuslaisin tai vasemmistolaisin? Voiko pelkkien taustatietojen perusteella arvata ehdokkaan puoluekannan? Mitkä kysymykset oppiva kone valitsee erotteleviksi?
Kaksi luokittelijaa Ylen vaalikonevastauksista
Luokittelijat on tehty Ylen vaalikoneen avoimen datan kaikille ehdokkaille yhteisten monivalintavastausten perusteella. Toinen perustuu saman datan taustatietoihin: ikä, sukupuoli, kieli, uskontokuntaan kuuluminen, tulot, työnantajan laatu, koulutus.
Ensimmäistä voi kutsua vaikkapa käyttäytymis- tai arvoperustaiseksi ja jälkimmäistä demografiaperusteiseksi. Käyn läpi lähinnä ensimmäistä, mielipiteisiin perustuvaa ja vähän demografiaperustaita.
Tekstin lopussa on lisätietoa siitä, mitä “luokittelu” tässä yhteydessä tarkoittaa - ja ihan lopussa on lyhyt tekninen kuvaus (tiivistelmä: glmnet:in multinomiaalimalli, regularisoinnissa käytetään L1-normia)
Puolueet ja määrät
Ylen vaalikonedatasta löytyy kokeiluun 1849 ehdokasta. Jätin suosiolla pois ne puolueet, joilla vastaajia on alle viisi. Luokittelija nimittäin yrittää minimoida kokonaisluokitteluvirhettä ja jos luokkien esiintymisellä on suuri ero, pienet luokat saattavat hävitä kokonaisvirheen pienentämiseksi, eikä ristiinvalidointiinkaan riitä dataa.
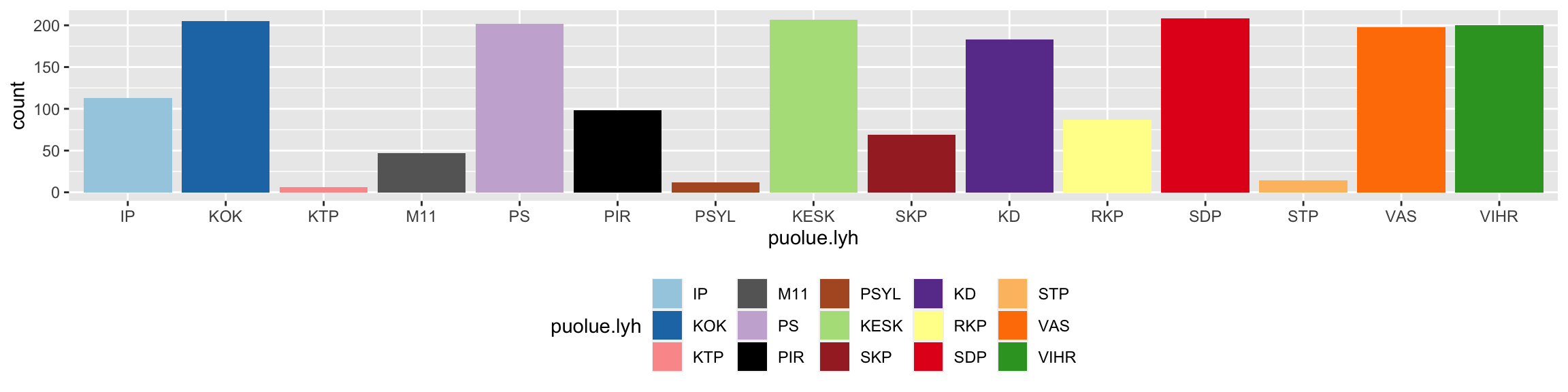
Nykyisten eduskuntapuolueiden lyhenteet lienevät selviä, muut lyhenteet ovat: Itsenäisyyspuolue (IP), Kommunistinen Työväenpuolue (KTP), Muutos 2011 (M11), Piraattipuolue (PIR) Pirkanmaan Sitoutumattomat yhteislista (PSYL), Suomen Kommunistinen Puolue (SKP) ja Suomen Työväenpuolue (STP).
Luokittelutulokset vastausten perusteella
Kolme neljästä luokittuu oikein
Malli antaa ristiinvalidoidun tarkkuusennusteen 76%. Noin 24% ehdokkaista luokittuu siis väärään puolueeseen, kun perusteena käytetään Ylen tekemiä kysymyksiä suoraan. Tätä voi suhteuttaa: jos ainoa informaatio (priori) olisi se, kuinka paljon puolueilla on ehdokkaita, olisi kannattavinta arvata aina SDP:ta, jolla on aineistossa eniten ehdokkaita, noin 11%.
Tulos on paljon arvausta parempi, kun priori on noin 11%. Ylen vaalikoneen datan perusteella yksinkertainen oppiva kone siis pystyy useimmiten tunnistamaan ehdokkaan puoluekannan. Kaipa puolueet sitten eroavat toisistaan.
Luokittelijan tai kysymysten käsittelyn muokkaamisella tulosta voisi ehkä parantaa, mutta se ei ole tekemäni lyhyen harjoituksen kannalta oleellista.
Sekaannusmatriisi
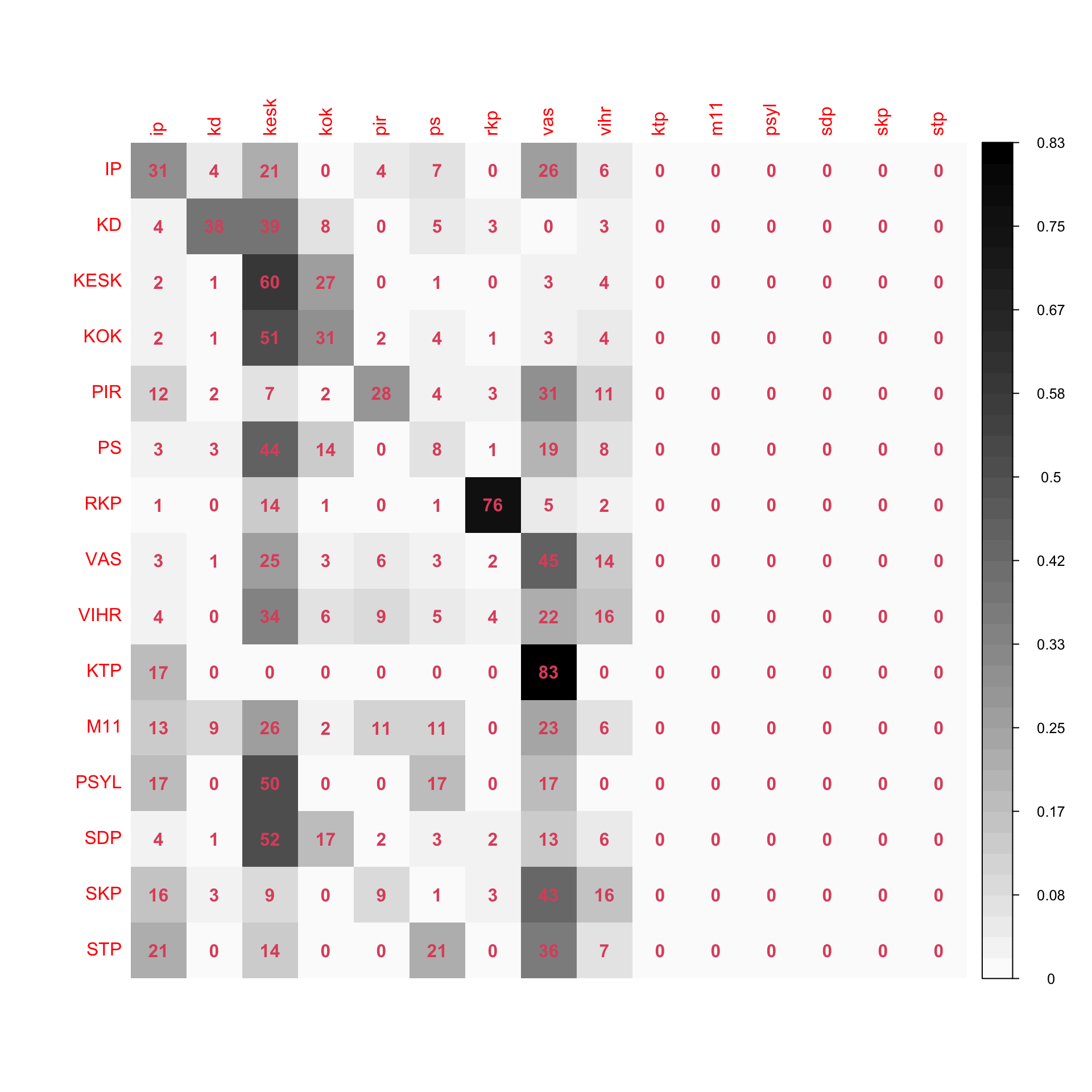
Virhe on eri suuruinen eri puolueilla ja puolueet sekaantuvat eri tavoin. Luokittelukokeessa ehkä mielenkiintoisinta onkin se, miten eri puolueet sekaantuvat toisiinsa vaalikonevastausten perusteella. Seuraavassa ehdokkaat on luokiteltu ja lasketaan, kuinka monta prosenttia kunkin puolueen ehdokkaista saa minkäkin ennustetun puolueen.
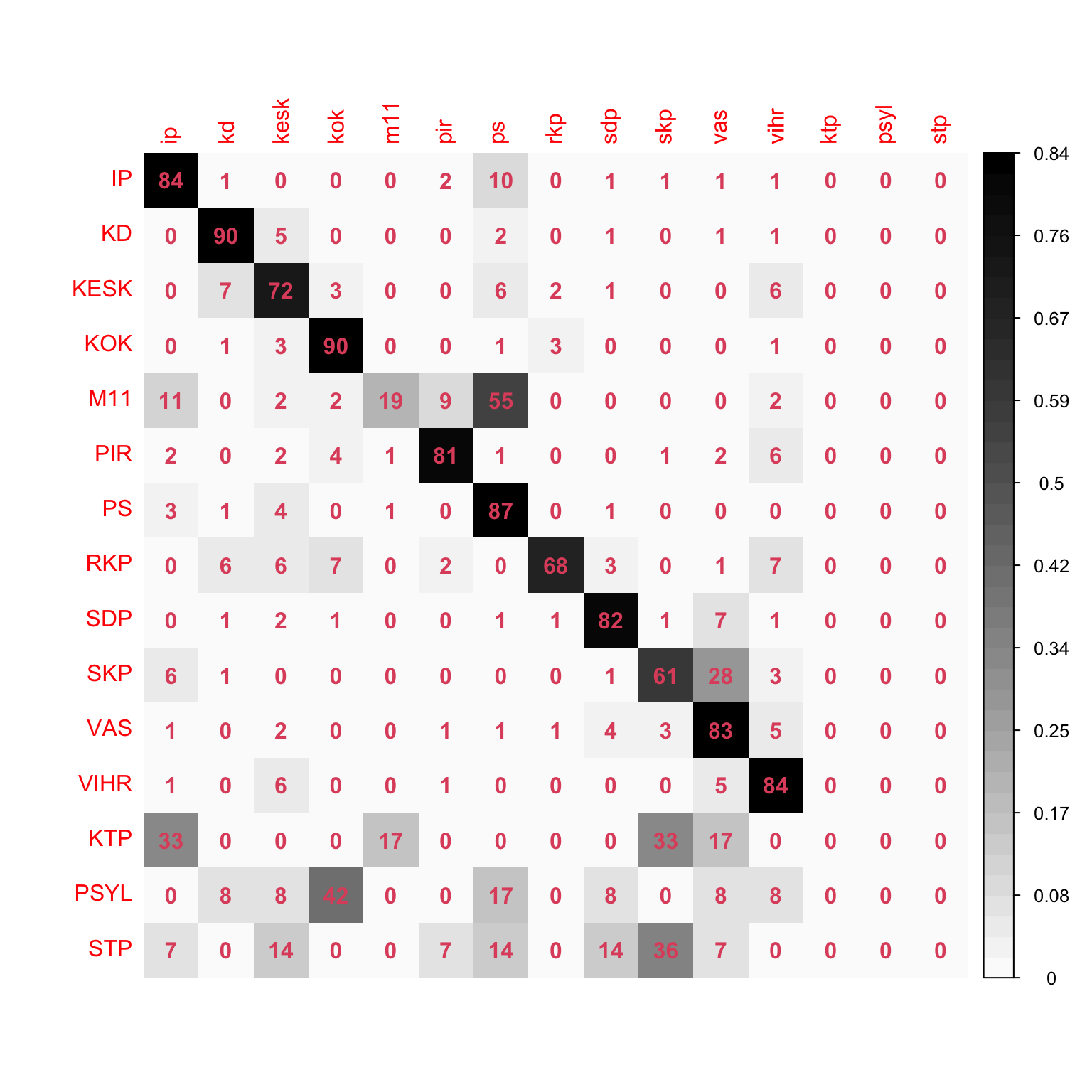
RIVIT kertovat oikean puolueen ja sarakkeet ennustetun. Luvut ovat prosentteja ja rivit summatutuvat noin sataan (prosenttiluvut pyöristettyjä).
Esimerkiksi Kokoomus ja Kristillisdemokraatit erottuvat hyvin, toisaalta näkyy kuinka pienten puolueiden/listojen ehdokaat luokitellaan isompiin: Kommunistinen Työväenpuolue, Pirkanmaan sitoutumattomat ja Suomen Työväenpuolue sirottuvat muihin puolueisiin. Puolueiden eri- ja samankaltaisuutta (Ylen kysymysten perusteella!) voi katsella matriisista: Esimerkiksi isoista puolueista Keskusta luokittuu heikoiten ja osaa luokittelija luulee vihreiksi, kristillisdemokraateiksi, perussuomalaisiksi tai kokoomuslaisiksi. SKP sekaantuu osittain Vasemmistoliittoon ja Muutos 2011 Perussuomalaisiin. Toisaalta esimerkiksi harva, jos kukaan vihreä luokittu kristillisdemokraatiksi tai kokoomuslainen vasemmistoliittolaiseksi.
Mennään henkilötasolle
Käytetty luokittelija toimii niin, että luokiteltava saa ennusteen todennäköisyydestä olla kunkin puolueen ehdokas. Tässä vaiheessa on hyvä vielä muistuttaa, että kaikkiaan tämä harjoitus mittaa Ylen kysymysten ja käytetyn menetelmän kykyä tehdä luokittelua, ei todellista aatten puhtautta ja paloa. Pienimmät puolueet luokittuvat sen verran huonosti, että olen reilu ja otan esimerkiksi kymmenen puoluetta, joilla on tässä aineistossa eniten ehdokkaita.
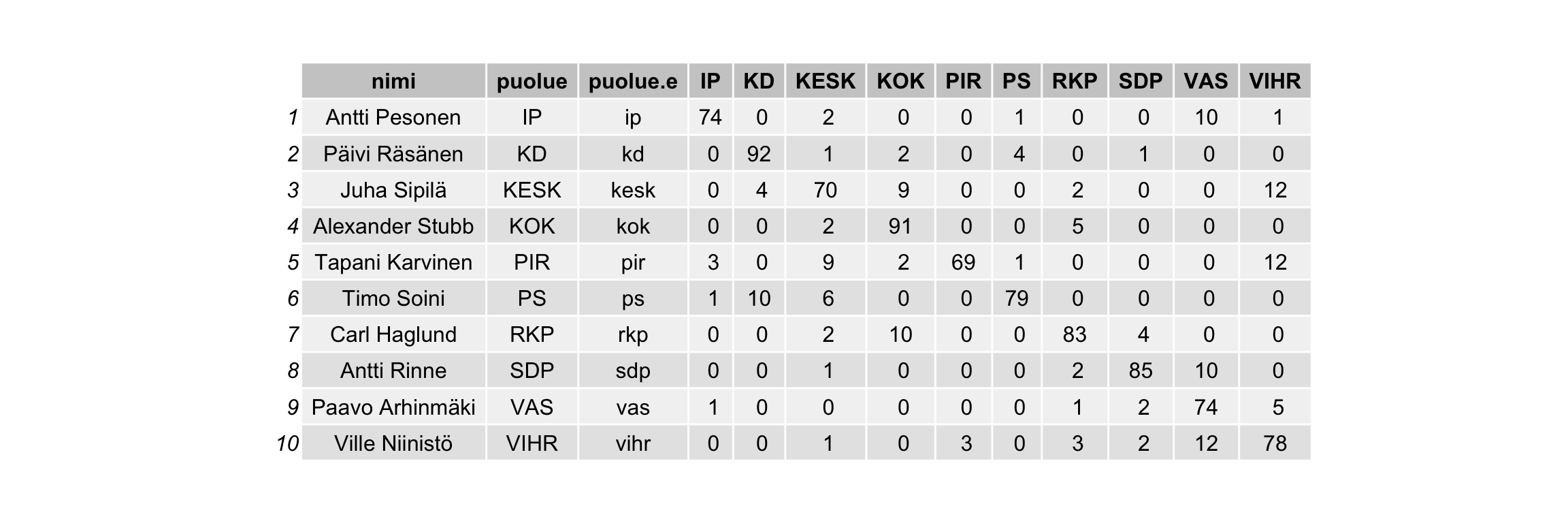
Sarakkeet ovat todennäköisyys (pyöristettynä kokonaisiin prosentteihin) kullekin luokalle (puolueelle). Pienimmät puolueet on jätetty pois joten rivit eivät summaudu aina sataan.
Helpotuksen huokaus: kaikki näiden puolueiden puheenjohtajat ennustuvat oikein ja vieläpä isolla marginaalilla seuraavaksi todennäköisimpään. On hauska pohtia, mitä tästä voisi nähdä. No, ainakin porvaripuolueiden puheenjohtajilla on hyvin pieni todennäköisyys luokittua Vasemmistoliittoon ja vastaavasti vasemmistopuolueiden puheenjohtajilla Kokoomukseen.
Kertoimet: mitä kone on oppinut?
Kertoimen etumerkistä voi päätellä, mihin suuntaan erottelevat kysymykset vaikuttavat. Yksinkertaistaen: kukin ehdokas saa saa kuulumisestaan luokkaan (puolueeseen) pisteluvun, johon vaikuttavat nollasta poikkeavat kertoimet. Jos kerroin on nolla, on samantekevää kyseisen puolueen suhteen, miten on vastannut. Pisteluku lasketaan joka puolueelle erikseen. Esimerkiksi myöteinen suhtautuminen perustuloon tuo pisteitä Vihreiden tai Keskustan ehdokkaana ololle, mutta kertoo päinvastaista sosiaalidemokraattien listoille kuulumisesta. KD:n ehdokkaillakin on asiaan kanta (keskimäärin keskimääräistä kielteisempi): nolla kertoo vain, että luokittelijan mielestä tätä kysymystä ei kannata huomioida kristillisdemokraattien kohdalla.
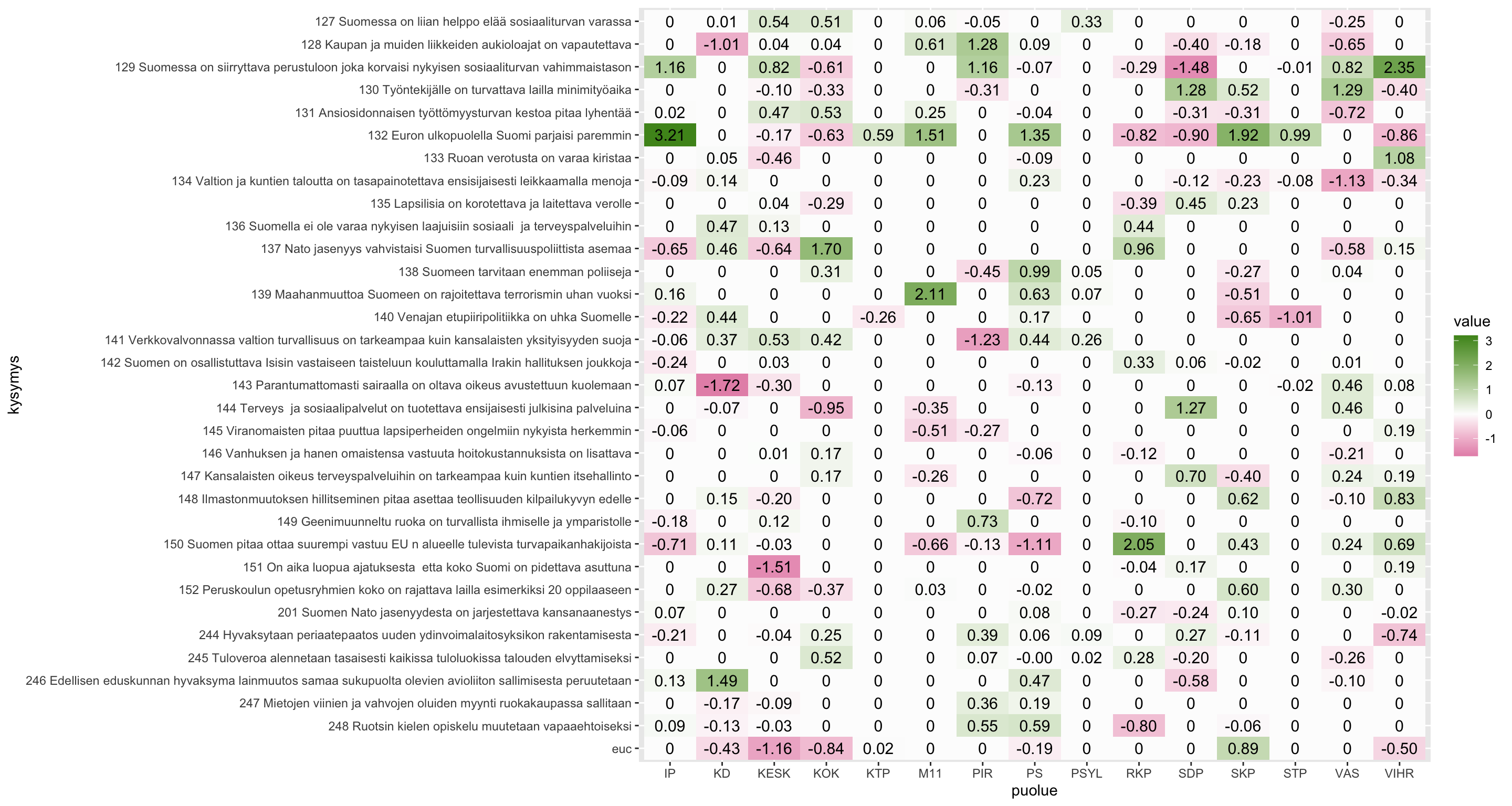
Entä tuo euc? Lisäsin yhden johdetun muuttujan, joka kertoo kuinka kauas nollatasosta (nollataso = ohita tai tyhjä) ehdokas on vastannut. Näyttää siltä, että luokittelija hyödyntää sitä. Esimerkiksi keskimääräistä “miedommin” vastaaminen puoltaa kuulumista Keskustan ehdokkaisiin. Samalla voi demonstroida sitä että kertoimet eivät kuvaa suoraan puolueiden suhteita keskimääräiseen, vaan sitä miten tietoa käytetään luokittelussa. Alla Tukeyn laatikkokaavio muuttujan euc arvoista eri puolueiile. Paksu viiva on mediaani.
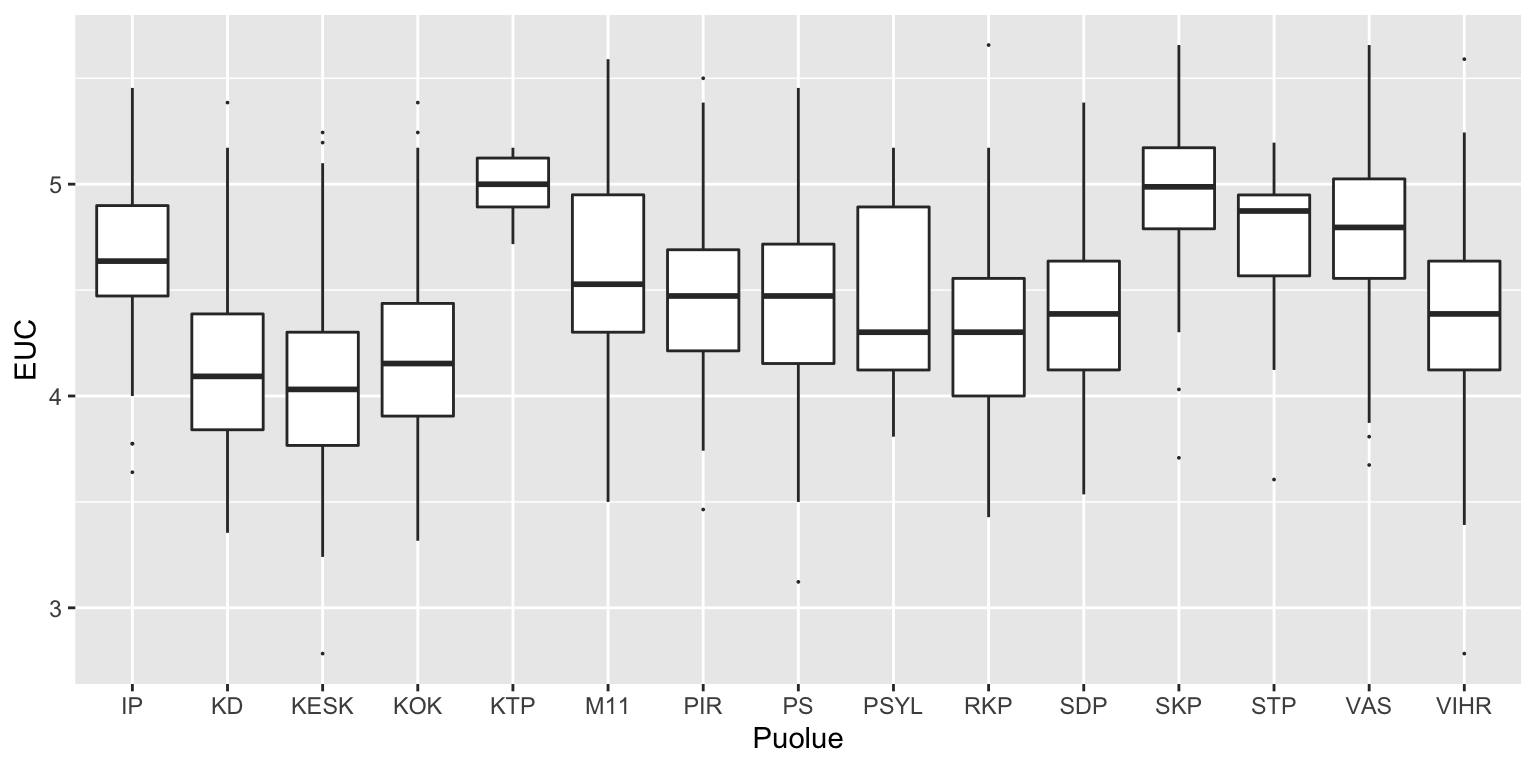
Esimerkiksi Vasemmistoliiton kerroin on nolla, vaikka ehdokkaissa on monia muita puolueita enemmän “jyrkkiä” vastaajia.
Istuvat vs. uudet ehdokkaat
Verrataan istuvien ja uusien ehdokkaiden luokittelun onnistumisprosentteja
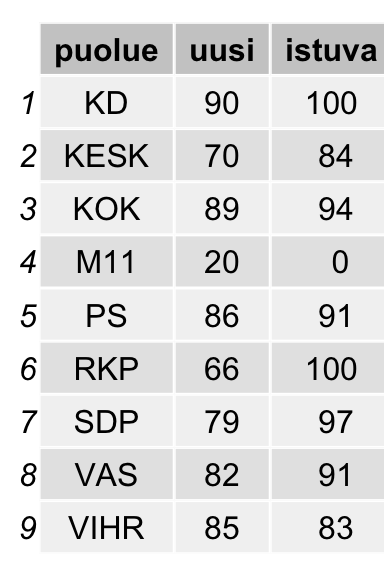
Istuvat luokittuvat selvästi paremmin. Määrät ovat pieniä, joten kokeilin sattuman välttämiseksi tehdä mallin pelkästään aineiston 159 istuvalla kansanedustajalla (pl. Muutos 2011, jolla on vain yksi edustaja), luokittelutarkkuus on ristiinvalidoituna 88 % tienoilla. Ryhmäkuri on sisäistynyt.
Demografinen luokittelija
Ylen datassa on taustatietoina mm. tulot, sukupuoli, äidinkieli, lapset, koulutus, työnantajan laatu (yksityinen/julkinen), uskontokunta ja sijoitukset. Kokeilin miten käy, jos käyttää vain näitä tietoja. Kokonaistarkkuus on 27%. Tulos on tietysti huonompi kuin mielipiteisiin perustuvalla luokittelijalla ja hyvä niin - mutta sentään arvausta selvästi parempi. Kun tarkastelee sekaannusmatriisia, huomaa että kyllä demografia ja tulot (tai se että ei halua näitä kertoa) tietyissä tapauksissa ehdokkaiden puoluekannoista kertoo. Itse asiassa RKP luokittuu paremmin kuin asiakysymysten avulla, avaintekijä on tässä äidinkieli. Keskusta on varmaankin “keskiluokkainen” taustaltaan ja vetää siksi monta ehdokasta. KD:n erottuvuutta muista porvaripuolueista selittää suuri sen suuri määrä muihin kristillisiin kirkkokuntiin kuuluvia, joita muissa puolueissa on vähän.
Mikä on luokittelija?
Luokittelu on koneoppimisen yksi perustehtävä. Luokiteltaville alkioille, tässä ehdokkaille, on olemassa oikea luokka, puolue. Lisäksi on selittävää dataa, tässä vastauksia kysymyksiin. Luokittelija muodostetaan käyttämällä aineistoa, jossa tunnetaan sekä selittävä data että oikea luokkatieto. Luokittelijalla voidaan sitten ennustaa oikean luokka muun datan perusteella, kun luokkatieto puuttuu.
Luokittelu on siis prediktiivinen, ennustava tehtävä. Tässä tapauksessa kaikille ehdokkaille tiedetään oikea puolue, Ennustuskykyä simuloidaan ristiinvalidoinnilla, jossa osaa ehdokkaista käytetään mallin muodostamiseen ja osalla validoidaan kuinka hyvin malli osaa ennustaa. Luokittelija ei voi tehdä ihmeitä: jos kysymykset eivät tuo informaatiota riittävästi, ei luokittelija sitä voi mistään taikoa. Yksi tapa lisätä luokittelukykyä on lisätä dataa, siis kysymyksiä, tai tehdä luokittelijan rakenteesta monimutkaisempi. Tässä piilee väärin tehtynä ansa: luokittelija ylioppii detaljeja ja alkaakin ennustaa uutta aineistoa yhä huonommin. Tätä vastaan taistellaan regularisoinnilla.
Käytän lineaarista logistista multinomiaalimallia, joka antaa myös ehdokkaille todennäköisyyden kuulua kaikkiin puolueisiin. Lisäksi luokittelijan kertoimet antavat kuvan siitä, millä perusteilla luokkapäätös on tehty. Käytän L1-sakkoa (“lasso”), joka jättää kokonaan huomiotta kysymyksiä, jotka sotkisivat luokittelua. Luokittimen kerroinmatriisiin jäävät vain (luokittimen mielestä) puolueelle riittävät ja yleistyskyvyn säilyttävät erottelevat muuttujat.
Lyhyt tekninen kuvaus
Vastausvaihtoehdot on muunnettu seuraavasti
- täysin eri mieltä / Ei = -1
- jokseenkin eri mieltä: -1/2
- ohita kysymys / Tyhjä: 0
- jokseenkin samaa mieltä: 1/2
- täysin samaa mieltä / Kyllä: 1
Lisäksi on laskettu muuttuja euc joka on vastausvektorin euklidinen etäisyys nollavektoriin, mikä siis kuvaa vastaustavan “äärimmäisyyttä” tai “laimeutta”.
(Demografiapohajaiseen luokittimeen vastaukset on 1-of-C -koodattu, puuttuva tieto eksplisiittisenä luokkana, ikä on likukuluku.)
Luokittelija on R:n glmnet -paketin multinomiaalimalli. Kokeessa on käytetty suoraan cv.glmnet -funktiota joka hakee regularisaatioparametrin 10-taitteisella ristiinvalidoinnilla.
classifier<-cv.glmnet(x,y,family="multinomial",type.measure="class",standardize=TRUE,intercept=TRUE,alpha=1)glmnet standardoi muuttujat itse ja asettaa intercept-termin. Vipu alpha=1 asettaa mallin käyttämään L1-sakkoa regularisoinnissa (“lasso”). (alpha=0 olisi L2-sakko ja tältä väliltä saataisiin “elastic net” -regularisointi.)
Kokeilin myös L2:ta, mutta tulos ei ollut ainakaan parempi.
Luokittelun kokonaisvirhe on parhaan mallin ristiinvalidaatiosta. Sekaannusmatriisin prosenttiluvut on puolestaan mallia sovellettu koko aineistoon, jolloin virhe on pari prosenttiyksikköä optimistisempi. Kokonaisvirhe olisi 21%, kun se ristiivalidoituna on siis 23,5%.
Koska muuttujia on suhteellisen vähän suhteessa dataan ja malli on lineaarinen ja glmnet:in regularisoinnin pitäisi olla laadukas, en ryhtynyt tekemään tästä sen ankarampaa validointia.
Lähdekoodi
Datan esikäsittelyyn ja luokitteluun käytetty skripti sekä esikäsitellyt datat löytyvät GitHubista.
Kaikkien ehdokkaiden lasketut todennäköisyydet kuulua kuhunkin puolueeseen löytyvät täältä.
Kirjoittaja Johan Himberg on data scientist Reaktorilla ja kävi jo äänestämässä eduskuntavaaleissa.
