Uusien vaaliaineistojen ja sosiaalisen median hyödyntäminen yhteiskuntatieteiden laskennallisiin menetelmiin perustuvassa tutkimuksessa on vasta aluillaan.

Verkosta on alkanut muodostua lupaava aarreaitta myös politiikan tutkijoille. (CC0)
Perinteisesti politiikan tutkimus on nojautunut pääasiassa laadullisiin menetelmiin, ja ehkä lähinnä vain vaalitutkimus on poikennut valtavirrasta tukeutumalla ensisijaisesti määrälliseen tutkimusotteeseen. Asetelman syy saattaa juontua aineistojen saatavuudesta. Sellainen inhimillinen toiminta jota politiikan monimutkaiset vuorovaikutusverkostot ja ilmiöt edustavat, taipuu vaivoin määrällisesti mitattaviksi suureiksi ja muuttujiksi. Vaalit muodostavat kuitenkin erityisen poikkeuksen tähän säännönmukaisuuteen. Äänestyspäätös ilmaistaan numeerisena arvona, ja se kytkeytyy ehdokkaan ja mahdollisesti edustajan arvoihin ja edelleen äänestyspäätöksiin, syntyviin lakeihin ja vallan rakenteisiin niin kansallisesti, paikallisesti kuin ylikansallisestikin. Toiseen suuntaan äänestyspäätös kytkeytyy kyselytutkimusten kautta myös äänestäjiin ja heidän demografisiin piirteisiinsä sekä arvoihin. Näin vaaleihin kytkeytyvä tutkimuskenttä voi tarkastella monin tavoin yhteiskunnan ja äänestäjien kollektiivisen tason ilmiöitä, kuten vallanjaon muutoksien syitä, äänestämisen ja osallistumisen kiinnostavuutta tai puoluekannatuksen taustatekijöitä.
Teknologian moninaisen hyödyntämisen yleistyminen ihmisten ja organisaatioiden päivittäisessä käytössä viime vuosikymmeninä on käynnistänyt politiikan tutkimuksen kannalta mielenkiintoisten aineistojen saatavuuteen liittyvän muutoksen. Yleisemmin ilmiötä on kutsuttu hieman eri rajauksin ja näkökulmin ajoin tietoyhteiskuntakehitykseksi, informaation vallankumoukseksi tai aikakaudeksi ja nyt viimeisimpänä digitalisaatioksi. Tälle ajalle on ominaista, että ihmisten välinen vuorovaikutus ja viestintä on teknologian välittämää. Niinpä jo suuri ja yhä kasvava osa inhimillisestä toiminnasta on jo syntyjään digitaalista tietoa, dataa, joka on myös mahdollisesti rakenteellista ja määrällisesti tarkasteltavissa.
Tässä artikkelissa tarkastellaan ensin big datan ja avoimen datan käsitteitä ja niiden kautta sitä minkälaisia aineistoja laskennallisia menetelmiä hyödyntävässä politiikan tutkimuksessa Suomessa on viime aikoina käytetty. Samalla nostetaan esille joitakin aineistoja hyödyntäneitä tutkimuksia ja menetelmiä.
Muotisanoja vai määriteltyjä käsitteitä?
Ensin on syytä määritellä mitä datalla tarkoitetaan ja minkälaisissa muodoissa se ilmenee. Data on digitaalisessa muodossa esiintyvää informaatiota. Sitä esiintyy tallennettuna erilaisille massamedioille, kuten kovalevyille, usb-muistitikuille tai cd-levyille. Inhimillisen tulkinnan kautta tämä digitaalinen informaatio voi jalostua tiedoksi, ja vielä syvällisemmin tietämykseksi.1 Datan määrää mitataan tavuina (engl. byte), ja yksi tavu koostuu kahdeksasta bitistä, jotka ovat arvoltaan aina ykkönen tai nolla. Bittien binäärinen, numeerisesti ilmaistava joko-tai -luonne linkittyy terminlogisesti digitalisaation käsitteeseen, joka viittaa laskemiseen. Suurten datamäärien ilmaisemiseen käytetään tavujen monikertoja, jotka tulevat kahden potensseista taulukon 1 mukaisesti.
Tavu = 8 bittiä
Kilotavu 2^10 = 1024 tavua
Megatavu 2^10 = 1024 kilotavua
Gigatavu 2^10 = 1024 megatavua
Teratavu 2^10 = 1024 gigatavua
Taulukko 1. Datan määrän ilmaiseminen.
Konkreettiset esimerkit auttavat määrien havainnollistamista, ja niitä löytyy runsaasti verkosta. Keskimääräinen englannin kielen sana vaati viisi tavua tallennustilaa, matalaresoluutioinen valokuva vie 100 kilotavua, raamatullinen tekstiä 4 megatavua ja ihmisen genomi 750 megatavua, joka mahtuu yhdelle cd-levylle. Yksi elokuva vie noin 5-7 gigatavua tallennustilaa, joka löytyy sopivasti DVD-levyltä. Huomionarvoista on, että ääni ja kuva, erityisesti liikkuva kuva, vievät moninkertaisesti tallennustilaa tekstiin verrattuna. Kokonaisen akateemisen kirjaston sisältö ottaisi 2 teratavua. Vuonna 2014 Facebook kertoi keräävänsä 600 teratavua käyttäjädataa päivässä.2
Datan määrän räjähdysmäinen kasvu on vaikuttanut “big datan” käsitteen yleistymiseen. Sitä ei yleensä käytetä viittaamaan mihinkään tarkkaan datamäärään, vaan käsite on monin tavoin suhteellinen. Yksi lähestymiskulma on, että kun perinteiset laitteistot, tietojärjestelmät, tietokannat ja ohjelmistot eivät kykene käsittelemään aineistoja, ainakaan inhimillisesti siedettävillä käsittelyajoilla, aletaan puhua big datasta. Tämä lähestymiskulma on luonnollisesti sidoksissa teknologiseen kehitykseen, tarkemmin laskentatehoon ja ohjelmistojen käsittelykykyyn, jotka käytännössä paranevat ajan myötä. Suuntaa-antavasti voidaan kuitenkin ilmaista, että esimerkiksi vuonna 2016 harvoin alle teratavun ainestoista puhutaan big datana.3
Toinen lähestymiskulma tarkastelee datan ominaisuuksia, niin kutsuttua kolmea v:tä: tilaa (volume), nopeutta (velocity) ja moninaisuutta (variety). Perinteisen tilan lisäksi päivitystahti, esimerkiksi videon suoralähetyksessä, striimauksessa kasvattaa nopeasti resurssien tarvetta. Moninaisuus taas esiinty esimerkiksi sosiaalisen median päivityksissä, jossa saattavat yhdistyä teksti, kuva, ääni ja videot, jolloin yksi perinteinen tietokanta ei taivu eri sisältömuotojen käsitelyyn -varsinkaan, kun viestejä lähetetään miljoonia tunnissa. Jotkut määrittelevätkin big datan sellaiseksi dataksi, jonka käsittely vaatii hajautettuja järjestelmiä. Hieman kriittisemmästä näkökulmasta big dataa pidetään yli-yksinkertaistavana markkinointiterminä, joka ei tarkoita välttämättä mitään eksaktia informaatioteknologian kanssa varsinaisesti työskenteleville.4
Tutkimuksen kannalta määrän ohella toinen olennainen datan ominaisuus on sen saatavuus, johon liittyy avoimen datan käsite. Avoimen datan käsitteen määritelmät vaihtelevat hieman eri lähteissä, mutta yhteistä on yleensä, että data on teknisesti ja luvallisesti kenen tahansa vapaasti käytettävissä, joka sisältää oikeuden edelleen jakaa ja julkaista muunneltuja jatkotuotoksia. Vapaa käyttö tarkoittaa pääsääntöisesti maksuttomuutta. Joissakin tapauksissa määreet “kenen tahansa” tai “mihin tahansa käyttötarkoitukseen” vaihtelevat ja jotkut saattavat viitatata avoimina myös sellaiseen dataan, jonka käyttöehdot kieltävät kaupallisen käytön tai rajaavat käyttötarkoituksia tai käyttäjäkuntaa muutoin tai vaativat esimerkiksi rekisteröitymistä tai muuta sopimuksenvaraisuutta. Tosin esimerkiksi Rufus Pollock kutsuu tällaista avoimuuspesuksi. Useimmat avoimen data käsitteenmääritelmät sisältävätkin vaatimuksen, jonka mukaan julkaisija ei julkaisun jälkeen aseta mitään rajoituksia jatkokäytölle -muuta kuin korkeintaan vaatimuksen julkaista jatkotyöt samalla avoimuuden säilyttävällä lisenssiehdolla.5
Uudet aineistot
Politiikan tutkimuksen kannalta relevanttien uusien aineistojen erittely tuo niin ikään uuden ongelman ratkaistavaksi aineistojen ryhmittely- tai luokitteluperusteen suhteen. Aineistoja voisi luokitella esimerkiksi ainakin sisällöntuottajien, aineiston omistajan tai sisältötyypin mukaan, eivätkä nämäkään tavat asettuisi välttämättä tai jopa todennäköisesti siisteihin luokkiin. Eri ominaisuuksien perusteella toisistaan erottuvia aineistotyyppejä ovat ainakin:
- sosiaalinen media
- yhteisöllinen tiedontuotanto
- vaali-aineistot
- järjestelmäpolitiikan päätöksenteko-aineistot
- talousdata
Todennäköisesti suurin ja käytetyin politiikan tutkimuksen uusi aineistolähde tulee sosiaalisen median keskusteluista. Kansainvälisesti suosituin lähde lienee Twitter. Suomessa Aller oy herätti huomiota julkaisemalla Suomi24-sivuston keskustelut epäkaupalliseen tutkimus- ja opetuskäyttöön.6 Maailman ylivoimaisesti käytön määrällä mitattu yksittäinen sosiaalisen median palvelu Facebook sen sijaan ei ole kokonsa veroinen aineistolähde. Vaikka osa käyttäjien päivityksistä on julkisia, ne eivät esimerkiksi nyt ole ohjelmallisesti saatavilla palvelun rajapinnasta7. Twitterin viestit sen sijaan ovat, ja ovat pääsääntöisesti aina olleet. Edellä mainittujen aineistojen lisäksi sosiaalista mediaa edustavat ainakin esimerkiksi YouTube ja blogit yleensä, mutta tämän artikkelin taustaselvityksessä ei tullut vastaan tutkimuksia, joissa niitä olisi käytetty tutkimusaineistona. Seuraavaksi tarkastellaan hieman lähemmin Twitteriä, Suomi24:ää ja vaaliaineistoja.
Tämän artikkelin lähteenä olevissa tutkimuksissa ja kirjoituksissa ei esitelty miltä Twitteristä saatava data näyttää, joten sen havainnollistamiseksi turvaudutaan Wei Xu:n Twitter-tutoriaaliin8 Ensin esitellään kuvakaappaus yksittäisestä twiitistä twitterin selainkäyttöliittymässä:
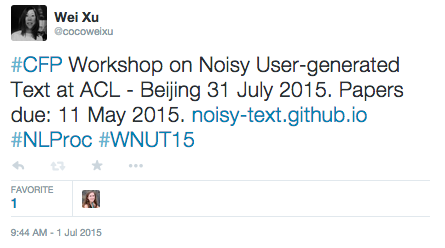
Kuva 1. Yksittäinen twiitti selainkäyttöliittymässä.
Twiitin voi ladata ohjelmallisesti yhdestä Twitterin rajapinnoista (API) JSON-datana. Tuolloin se näyttää tekstieditorissa taulukon 2 mukaiselta.
{
"favorited": false,
"contributors": null,
"truncated": false,
"text": "#CFP Workshop on Noisy User-generated Text at ACL - Beijing 31 July 2015. Papers due: 11 May 2015. http://t.co/rcygyEowqH #NLProc #WNUT15",
"possibly_sensitive": false,
"in_reply_to_status_id": null,
"user": {
"follow_request_sent": null,
"profile_use_background_image": true,
"default_profile_image": false,
"id": 237918251,
"verified": false,
"profile_image_url_https": "https://pbs.twimg.com/profile_images/527088456967544832/DnclpoZO_normal.jpeg",
"profile_sidebar_fill_color": "DDEEF6",
"profile_text_color": "333333",
"followers_count": 226,
"profile_sidebar_border_color": "C0DEED",
"id_str": "237918251",
"profile_background_color": "C0DEED",
"listed_count": 13,
"profile_background_image_url_https": "https://abs.twimg.com/images/themes/theme1/bg.png",
"utc_offset": null,
"statuses_count": 120,
"description": "I am a postdoctoral researcher @PennCIS, studying Natural Language Processing and Social Media.",
"friends_count": 166,
"location": "Philadelphia PA",
"profile_link_color": "0084B4",
"profile_image_url": "http://pbs.twimg.com/profile_images/527088456967544832/DnclpoZO_normal.jpeg",
"following": null,
"geo_enabled": true,
"profile_background_image_url": "http://abs.twimg.com/images/themes/theme1/bg.png",
"name": "Wei Xu",
"lang": "en",
"profile_background_tile": false,
"favourites_count": 88,
"screen_name": "cocoweixu",
"notifications": null,
"url": "http://www.cis.upenn.edu/~xwe/",
"created_at": "Thu Jan 13 23:15:12 +0000 2011",
"contributors_enabled": false,
"time_zone": null,
"protected": false,
"default_profile": true,
"is_translator": false
},
"filter_level": "low",
"geo": null,
"id": 616333141884674048,
"favorite_count": 0,
"lang": "en",
"entities": {
"user_mentions": [],
"symbols": [],
"trends": [],
"hashtags": [{
"indices": [0, 4],
"text": "CFP"
}, {
"indices": [124, 131],
"text": "NLProc"
}, {
"indices": [132, 139],
"text": "WNUT15"
}],
"urls": [{
"url": "http://t.co/rcygyEowqH",
"indices": [99, 121],
"expanded_url": "http://noisy-text.github.io",
"display_url": "noisy-text.github.io"
}]
},
"in_reply_to_user_id_str": null,
"retweeted": false,
"coordinates": null,
"timestamp_ms": "1435780246598",
"source": "<a href=\"http://twitter.com\" rel=\"nofollow\">Twitter Web Client</a>",
"in_reply_to_status_id_str": null,
"in_reply_to_screen_name": null,
"id_str": "616333141884674048",
"place": null,
"retweet_count": 0,
"created_at": "Wed Jul 01 19:50:46 +0000 2015",
"in_reply_to_user_id": null
}
Taulukko 2. Twiitti JSON-muodossa.
140 merkin twiitti muuttuukin tässä esimerkissä 2731 merkiksi, kun kaikki tietueet ja kentät lasketaan yhteen. Eri kentät kuvaavat twiitin eri ominaisuuksia ja metatietoja. JSON-muotoisen datan- rakenne muodostuu yksinkertaisesti kahdesta osasta, joka on mallia “nimi” : “arvo”. Useampia yhteenkuuluvia nimiä ja arvoja voidaan niputtaa kaari- ja hakasulkeiden sisään. Esimerkiksi kenttä “text” sisältää twiitin varsinaisen tekstin. Juuri datan rakenteellinen muoto luo edellytykset tehokkaalle ja ohjelmoijille helpolle käsittelylle. Sen lisäksi verkosta löytyy runsaasti maksuttomia ja kaupallisia oppaita.9
Twitterin käyttöä vaalikampanjoinnissa on tutkittu laskennallisin menetelmin vuonna 2012 Datavaalit-hankkeessa10. Sen taustalla on eräänlaista hakkerietiikkaa edustava avoin tutkija- ja koodaajayhteisö, jossa myös Louhos-blogin kirjoittajat ovat olleet mukana. Leo Lahden ym. mukaan kunnallisvaaleissa 2012 vihreät ja kokoomus olivat Twitterin aktiivisimmat puolueet. Miehet twiittasivat yli kaksi kertaa niin usein kuin naiset. Aktiivisimmat ehdokkaat twiittasivat jopa 2000-5000 kertaa.11
Samankaltaisesti nimetyssä, mutta eri tutkijoiden Digivaalit 2015 -hankkeessa Twitteriä hyödynnettiin keskeisenä aineistolähteenä eduskuntavaalien tarkastelussa. Hankkeen tutkijat Matti Nelimarkan johdolla latasivat Twitterin rajapinnasta ainakin yli 200 000 viestiä12. Aineisto on kerätty pääosin eduskuntavaaleja edeltävältä ajalta, mutta osa tutkimuksista kohdistuu myös vaalien jälkeiseen aikaan. Twiitit ovat tallennettu tekstitietokannaksi.13 Salla-Maria Laaksosen mukaan vaaleja ei voi sanoa vielä twitter-vaaleiksi, sillä vain 938 kaikkiaan 2146 ehdokkaasta oli ylipäätään mukana twitterissä. Sen sijaan nimitys hashtag-vaalit saattaisi kuvata vaalien luonnetta paremmin14.
Hankkeessa on tehty useita eri tutkimuksia ja julkaisuja, joilla on vielä tarkemmat omat aineistorajauksensa, eikä kaikissa tapauksissa ole käytetty koko aineistoa. Mari Marttila on tutkinut osuvasti ja leikkisästi nimetyssä pro gradussaan otsikolla #vainkansanedustajajutut kansanedustajien twitter-tilien, twiittien ja keskustelun määrää15. Arto Kekkonen tarkasteli #koulutuslupaus-kampanjan tavoitteita ja twitter-keskustelua 14 235 aiheen mukaisesti tägätyn twiitin avulla16. Mari Tuokko tutki 433 keskusteluketjun (erittelemättä sekä Twitter- että Facebook -ketjuja) avulla ehdokkaiden ja kansalaisten välistä vuorovaikutusta sosiaalisessa mediassa. Tutkimuksen analyysi kohdistui yksittäisten viestien tasolle sekä laadullisella että määrällisellä otteella. Tarkastelulla pyrittiin selvittämään sekä vuorovaikutuksen funktioita että topiikkeja.17 Toisessa tutkimuksessa Tuokko ja tutkimusryhmä tarkastelivat #olohuonetentti -kampanjaa, joka osoitti, että joissakin tapauksissa twitter-keskustelu rikkoo perinteiset puoluerajat.18
Yksi Digivaalit-hankkeen merkittävimmistä tutkimuskohteista lienee verkon vaikuttajaindeksin laskemismenetelmän kehittäminen. Sen selvittämiseksi 167 395 Twitter- ja Facebook-viestiä vertailtiin 5427 politiikkaa koskevaan uutiseen 19 eri median sivuilta ja 80 456 kansalaisten #vaalit2015, #vaalit ja #politiikka -tunnisteilla julkaisemaan sosiaalisen median viestiin. Tutkimuksen tuloksena aineistosta erottautui joukko niin kutsuttuja supervaikuttajia, jotka saavat äänensä kuuluviin sosiaalisen median ansiosta myös perinteisen median puolelle.19
Tweetit ovat hyvä esimerkki avoimesta datasta politiikan tutkimuksessa. Pääosa tweeteistä ovat sekä julkisia ja helposti ihmisluettavassa muodossa että avoimien rajapintojen kautta myös koneluettavassa muodossa ja siten hyvää raaka-ainetta laskennallisille tutkimusmenetelmille. Muutamat kymmenet tuhannet akiiviset suomalaiset twiittajaat muodostavat verrattain pienen käyttäjäjoukon, varsinkin twitter-keskusteluaineistojen big dataksi luokittelemisen kannalta. Sen sijaan kansainväliset, yleensä englanninkieliset otokset voivat helposti kasvaa suuriksi ja jatkuvan päivittymisen ansiosta muodostaa loputtoman aineistolähteen. Se herättääkin pohtimaan kysymystä siitä, täytyisikö tutkijoiden jättää tutkimusohjelmakoodinsa pyörimään palvelimelle itsekseen, jotta tutkimustulokset voivat päivittyä automaattisesti aineiston lisääntyessä?
Suomi24
Krista Lagus, Mika Pantzar, Minna Ruckenstein ja Marjoriikka Ylisiurua ovat kuvailleet Suomi24-keskusteluaineistoa julkaisemassaan “Suomi24 - Muodonantoa aineistolle” -raportissa. Erillinen tutkimusjulkaisu pelkästä aineistosta itsestään kuvaa hyvin big data -aineistojen laajuutta ja sisällöllistä moninaisuutta, jonka hahmottaminen vaatii alkuun oman aikansa ennen varsinaiseen tutkimukseen ryhtymistä. Aineisto koostuu Suomi24-verkkokeskustelufoorumille käyttäjien kirjoittamista viesteistä. Keskustelu on organisoitu useisiin erilaisiin alueisiin, kuten Suhteet, Ajoneuvot ja liikenne tai Yhteiskunta, joka on suurin yksittäinen keskustelualue. Alueet jakaantuvat vielä alatasoille jopa kuudennelle tasolle, ja aina alimmalla tasolla sijaitsevat keskusteluketjut. Yksittäinen viesti voi aloittaa uuden ketjun tai kommentoida vanhaa olemassaolevaa ketjua.20
Lagus ym. kirjoittavat, että “Suomi24-aineisto on avattu tutkimuskäyttöön avoimen datan hengessä”21. Ilmaisu pitää sinällään paikkansa, että aineisto ei ole kovin monen määritelmän mukaan kaikille avointa dataa, vaan se on sopimuksenvaraisesti määrättyihin käyttötarkoituksiin julkaistua dataa. Tutkijoiden näkökulmasta aineiston käytössä ei ole kuitenkaan saatavuuteen liittyviä ongelmia, joten se näyttäytyy tieteen kannalta avoimena aineistona.
Data on saatavilla tutkimuskäyttöön joko Allerilta suoraan päivittyvästä rajapinnasta sopimuksella tai Kielipankista korkeakoulujen tutkijoiden käyttäjätunnuksilla kerralla yhtenä pakettina. Se on tarjolla sekä JSON-muodossa että kielitieteellisesti rikastetussa VRT-muodossa. Ensin mainitussa kommentit näyttävät taulukon 3 mukaiselta:
{
”body”: ”<p>Mukavasti on pukannut uusia S6 ja A8 Audeja liikenteeseen t\u00e4\u00e4ll\u00e4 Turun seudulla!!!</p>”,
“closed_reason”: “inactivity_time_reached”,
“views”: 308,
“deleted”: false,
“topics”: [{“title”: “Ajoneuvot ja liikenne”, “topic_id”: 2},
{“title”: “Autot”, “topic_id”: 6254},
{“title”: “Automerkit”, “topic_id”: 1109},
{“title”: “Audi”, “topic_id”: 3256}],
“title”: “Audia pukkaa....”,
“comments”: [{“body”: “<p>pukkas 70:t\u00e4 luvulla Ladaa liikkuu jyv\u00e4skyl\u00e4ss\u00e4!</p>”,
“quote_id”: 0, “deleted”: false, “created_at”: 1207988326000, “comment_id”: 29898190,
“anonnick”: “krigg”, “thread_id”: 5604224, “parent_comment_id”: 0}],
“anonnick”: “SS66AA88”,
“thread_id”: 5604224,
“closed”: true,
”created_at”: 1207910044000
}
Taulukko 3. Suomi24-keskusteluketju JSON-muodossa.
Esimerkissä on ensin nimimerkin “krigg” kirjoittama ketjun aloitusviesti otsikolla “Mukavasti on pukannut uusia S6 ja A8 Audeja liikenteeseen täällä Turun seudulla!!!” ja siihen nimimerkin “SS66AA88” vastaus “pukkas 70:ta luvulla Ladaa liikkuu jyväskylässä!”.
Suomi24 -aineisto on kertynyt vuodesta 2001 alkaen ja sitä kerääntyy toistaiseksi koko ajan. Palveluun on kirjoitettu sen olemassaolon aikana viestien juoksevan id-tunnistenumeron perusteella yli 80 miljoonaa viestiä. Tosin näistä suuri osa on poistettu tai virheellisiä kirjauksia, sillä ladattu aineisto käsittää noin 60 miljoonaa viestiä. Yksittäiset viestit voivat olla lyhyitä tai hyvinkin pitkiä, satoja sanoja, mutta keskimäärin viestit ovat lauseen, eli 5 - 10 sanan pituisia. Ketjujen elinikä vaihtelee myös suuresti, ja osa aloitetuista ketjuista ei saa lainkaan vastauksia, kun taas toisiin palataan vielä vuosien päästä.
Aineistoa on jo hyödynnetty joissakin tutkimuksissa. Veikko Eranti ja Tuukka Ylä-Anttila etsivät esipoliittisia keskusteluaiheita ihmisten arkipäiväisistä verkkokeskusteluista laskennalllisen aiheenmallinnus (topic modelling) -menetelmän avulla. He tunnistivat 21 aihetta, joiden muodostama aineisto voi toimia raaka-aineena esimerkiksi tarkemmalle laadulliselle analyysille.22 Kesällä 2015 Helsingissä järjestettiin Suomi24-aineistoon keskittyvä hackathon, jossa eri ryhmät sovelsivat erilaisia laskennallisia menetelmiä kokeellisesti ja pienimuotoisesti aineiston tutkimiseksi. Osallistujat tutkivat esimerkiksi keskustelujen ennustuskykyä talouden suhdanteisiin, kateutta ilmaisevien keskustelujen ajallisia vaihteluita ja keskusteluaiheita, jotka johtavat lyhyisiin tai pitkiin keskusteluketjuihin.23
Vaali-aineistot
Vaalit ovat kvantitatiivisen politiikan tutkimuksen perinteisesti suurin ja vaikuttavin aineistolähde. Vaalituloksen ja kyselytutkimusaineistojen rinnalle viime vuosina on noussut kuitenkin uusia mielenkiintoisia aineistolähteitä. Valtiontalouden tarkastusviraston vuodesta 2009 alkaen keräämät vaali- ja puoluerahoitusilmoitukset ovat muodostuneet varteenotettavaksi tutkimusaineistoksi vaalirahakohun seurauksena. Ilmoitukset ovat luettavissa verkkopalvelussa ja lisäksi virasto raportoi tarkastuksensa vaaleittain.24
Virallisten julkaisujen lisäksi Datavaalit-yhteisö on uudelleenjulkaissut siistittynä ja alkuperäislähteitä helpommin jatkokäytettävässä muodossa muiden muassa oikeusministeriön vaalituloksia, ehdokkaiden Facebook- ja Twitter-päivityksiä sekä vaalirahoitusilmoituksia.25
Yksi merkittävimmistä uusista aineistolähdetyypeistä ovat vaalikone-aineistot. Erityisesti Helsingin Sanomat ja Yle ovat julkaisseet sekä ehdokkaiden että joissakin tapauksissa myös vaalikoneiden käyttäjien vastauksia avoimena datana.26 Vanhin julkaistu aineisto on Helsingin sanomien eduskuntavaalien 2011 alla julkaisema eduskuntavaalien 2007 aineisto.27 Tämän jälkeen sekä Yle että HS ovat julkaisseet kaikkien eduskuntavaalien ja presidentinvaalien ehdokkaiden aineistot. Myös MTV on avannut presidentinvaalien 2006 aineistot.28 Yksittäistapauksissa mediatalot ovat julkaisseet myös euro- ja kunnallisvaalien aineistoja.
Helsingin Sanomien ja Ylen vaalikoneaineistot ovat pääsääntöisesti tarjolla verkkosivuilla julkaistun linkin kautta suoraan palvelimelta ladattavina tiedostoina. Aineistojen lisenssit ovat tyypillisesti vapaasti tai ei-kaupallisesti käytettäviä, kunhan lähdeviite mainitaan muutettuja töitä julkaistaessa. Joissakin tapauksissa aineistot ovat tarjolla päivittyvässä muodossa rajapinnan kautta, jonka käyttäminen edellyttää rajapinta-avaimen pyytämistä toimitukselta. Suorien pakettien tapauksessa aineistot ovat todella avoin dataa. Myös Yhteiskuntatieteellinen tietoarkisto on kerännyt samoja aineistoja ja jakaa niitä omassa Aila-palvelussaan, mutta erikoisesti huomattavasti rajoitetuilla käyttöehdoilla, joissa jopa tarkkaan määritellään minkä tasoiseen tutkimukseen aineistoja saa käyttää.29
Ehdokkaiden ja käyttäjien vastauksia
Vuoden 2015 eduskuntavaalien Ylen aineisto sisältää 2147 ja HS:n 1764 riviä, joissa kummassakin yhden ehdokkaan vastaukset ovat yhdellä rivillä. Ylen data on csv-muodossa yksinkertaisesti tekstinä pilkulla erotettuina arvoina ja HS:n data excel-taulukkona. Käytännössä muodot ovat yhtä lailla käytettävissä ja helposti konvertoitavissa suuntaan tai toiseen missä tahansa taulukkolaskentaohjelmassa tai ohjelmointiin tarkoitetussa tekstieditorissa. Vastaukset löytyvät sarakkeilta ja Ylellä kysymyksiä on yli sata sekä jokaisella kysymyksellä on omana tietueenaan avovastauksen mahdollisuus. Helsingin Sanomilla kysymyksiä on vain 30. Lisäksi kummallakin on kustakin ehdokkaasta yleistietoja liittyen sukupuoleen, ikään, ammattiin, alueeseen sekä verkkonäkyvyyteen eli kotisivuihin ja sosiaaliseen mediaan. Datan tallennustavassa on sellainen ero, että Ylen datassa vastaukset ovat tekstinä sarakkeissa kun taas HS:n datassa ne ovat numeerisina arvoina. Ylen tapa lienee helppolukuisempi ihmissilmälle, mutta HS:n tapa suoraviivaisempi ohjelmalliseen käsittelyyn ja vie myös huomattavasti vähemmän tilaa.30
Ehdokkaiden vastausten lisäksi joissain vaaleissa vaalikoneiden tarjoajat ovat julkaisseet myös palveluiden käyttäjien vastauksia. Tällöin datan määrä ja samalla potentiaalinen tutkimuksellinen hyöty kasvaa huomattavasti. Helsingin Sanomien varhaisia vaalikoneaineistojulkaisuja olivat vuosien 2007 eduskuntavaalien ja 2009 europarlamenttivaalien vaalikoneiden käyttäjien vastausten aineistot.31 Seuraavassa on (luettavuuden helpottamiseksi rivitettynä) otsikkorivit ja yksi rivi dataa vuoden 2007 aineiston alusta:
"Inner_id";
"User_id";
"Age_group";
"Sex";
"Area_id";
"Election_year";
"winnerCandidate";
"winnerParty";
"Answers";
"CandidatesList";
"PartiesList";
"Created";
"Modified"
"4569";
"11718105386517402";
"0";
"n";
"1020";
"2007";
"3240";
"Kokoomus";
"20:1:134:1:2:;21:2:0:0:2:;22:3:0:0:2:;23:4:0:0:2:;24:5:0:0:2:;25:6:0:0:2:;26:7:0:0:2:;27:8:0:0:2:;28:9:0:0:2:;29:10:0:0:2:;30:11:0:0:2:;31:12:0:0:2:;32:13:0:0:2:;33:14:0:0:2:;34:15:0:0:2:;35:16:0:0:2:;36:17:0:0:2:;37:18:0:0:2:;38:19:0:0:2:;39:20:0:0:2:;40:21:0:0:2:;41:22:0:0:2:;42:23:0:0:2:;43:24:0:0:2:;44:25:0:0:2:;45:26:0:0:2:;46:27:229:3:2:;";
"3240:663:Pynnönen:Jarmo:Kok:83;4316:623:Luoma-Nirva:Jarno:Lib:57;2513:540:Hyttinen:Ilkka:Ipu:120;3233:398:Hyytiäinen:Sari:Kok:76;3232:392:Heinonen:Timo:Kok:75;2898:382:Sutinen:Reijo:Skp:53;3462:380:Nissilä:Minna:Kesk:67;3242:377:Vahter:Merja:Kok:85;3243:373:Viljanen:Ilkka:Kok:86;3463:367:Penttilä:Mika:Kesk:68;999999999:0:0:0:0:0;4162:-600:Savolainen:Leena:Vas:13;2628:-601:Raappana:Paavo:Vihr:116;4164:-629:Toivonen:Sari:Vas:15;";
"Ipu:129:19:3;Kai Aaltonen:-287:32:1;Kd:-37:14:8;Kesk:-65:10:13;Kok:269:12:14;Lib:623:20:1;Ps:-38:17:10;Sdp:-381:11:13;Skp:-352:26:7;Sks:-397:25:1;Stp:-571:18:1;Vas:-450:16:14;Vihr:-316:15:12;";
"2007-02-18 16:55:38";
"2007-02-18 16:55:38"
Taulukko 4. Helsingin Sanomien vuoden 2007 eduskuntavaalien vaalikoneen yhden käyttäjän vastaukset csv-muodossa.
Data kertoo siis esimerkiksi vastaajan ikäryhmän, sukupuolen, vaalipiirin, vastaajalle sopivimmat ehdokkaat ja puolueet sekä vastaukset vaalikoneeseen. Vuoden 2007 aineisto sisältää 384694 riviä ja vuoden 2009 aineisto 228 476 riviä. Aineistojen tietorakenteet ovat samanlaiset.
Ylen vuoden 2012 presidentinvaalien vaalikoneaineiston julkaisu sisältää käyttäjien vastaukset, joita on 244 976 riviä. Kysymykset löytyvät sarakkeilta, joita on 20. Vastaukset ovat numeerisina arvoina ja niiden selitteet löytyvät datan julkaisun verkkosivuilta. Ehdokasaineistoista poiketen käyttäjistä ei ole mitään kuvailevaa tai identifoivaa dataa.32
Helsingin Sanomat julkaisi vuoden 2012 presidentinvaalien aineistosta sekä ehdokkaiden että käyttäjien vastaukset, mutta hieman tavallista rajoitetummalla, uudelleenjulkaisun kieltävällä lisenssillä ja vain rajapinnan kautta.33 Aineistoa ei ladattu ja tutkittu suoraan tätä artikkelia varten, mutta Louhos-tutkijaryhmä on julkaissut kuvaajia aineistosta, jotka erittelevät kuinka vastaajat jakautuvat eri demografisten piirteiden mukaan. Aineisto sisältää yli 200 000 käyttäjän vastaukset.34 Aineiston luotettavuuteen liittyy joitakin reunaehtoja, mutta se tarjoaa kokonsa vuoksi huomattavasti ilmaisuvoimaa tilastolliseen tarkasteluun.35
Vuoden 2012 Kuntakoneesta HS julkaisi myös n. 11 000 käyttäjän vastaukset. Aineisto sisältää yksinkertaisuudessaa vastaajan kotikunnan ja toisessa sarakkeessa ne kunnat, joiden haluaisi muodostavan kuntaliitoksen.36 Erityisesti juuri vaalikoneiden käyttäjien vastaukset sisältävät aineistot ovat mahdollistaneet vaaleissa valittujen ehdokkaiden, kaikkien ehdokkaiden ja kansalaisten arvojen vertailut.
Vain ehdokkaiden vastaukset sisältävät vaalikoneaineistot ovat tyypillisesti muutamien tai joidenkin kymmenien megatavujen kokoisia, jolloin niistä puhuminen big datana ei välttämättä ole oikein oikeutettua. Sen sijaan käyttäjien vastaukset sisältävät aineistot ovat useita satoja megatavuja, ja hieman ohjelmasta ja koneesta riippuen aineistojen käsittely saattaa olla enemmän tai vähemmän sujuvaa. Esimerkiksi Helsingin Sanomien vuoden 2007 pakkaamaton 500-megatavuinen aineisto osoittautui ylivoimaiseksi Open Officelle ja suhteellisen tehokkaalle tietokoneelleni, jossa on i5-prosessori ja 8 Gt työmuistia. Näin ollen ainakin yhden näkökulman mukaan big datan mainitseminen tällaisten aineistojen yhteydessä voi olla perusteltua.
Tutkimuksellista “pikaruokaa” vaalikonedatasta
Vaalikoneainestoja on hyödynnetty hyvin monipuolisesti. Tavat vaihtelevat yksinkertaisista kehittyneisiin tilastollisiin menetelmiin, visualisointeihin kuten ehdokkaiden ja puolueiden arvokarttoihin ja sisällöllisiin tutkimuksiin, jossa hallitusohjelmaa vertaillaan vastauksiin tai se uudelleenkirjoitetaan niiden perusteella. Seuraavat esimerkit eivät edusta perinteistä tieteenteon “hidasta” tapaa vaan päinvastoin, informaatioajalle ominaista ketterää lähestymistapaa.
Yksinkertaisia vastausten jakaumia edustavia tutkimuksia edustavat esimerkiksi Jouni Tuomiston ym. Kansanedustajien arvot -artikkeli, joka selvitti eniten samanmielisyyttä ja toisaalta erimielisyyttä herättäneitä kysymyksiä.37 Ehkä kaikkein suosituin tapa vaalikonevastausten hyödyntämiseen ovat olleet erilaiset visualisoinnit, jotka sijoittavat kansanedustajat arvokartalle eri ristiriitaulottuuvuksien suhteen, kuten kuvassa 2. Ne ovat havainnollistavia, toimivat yksilö- ja puoluetasolla sekä parhaimmillaan visuaalisesti näyttäviä että käytettävyydeltään hyviä, joskus jopa addiktiivisia.38
 Kuva 2. Martti Leppäsen visualisoima kansanedustajien ja puolueiden arvokartta. Ulla-Maj Wideroosin arvot sijoittuvat aivan keskelle sekä vasemmisto-oikeisto että konservatiivi-arvoliberaali -ulottuvuuksa. Kuvakaappaus Helsingin Sanomien sivuilta.
Kuva 2. Martti Leppäsen visualisoima kansanedustajien ja puolueiden arvokartta. Ulla-Maj Wideroosin arvot sijoittuvat aivan keskelle sekä vasemmisto-oikeisto että konservatiivi-arvoliberaali -ulottuvuuksa. Kuvakaappaus Helsingin Sanomien sivuilta.
Niiden taustalla olevat valinnat eri ristiriitaulottuvuuksien valinnasta, tilastollisista menetelmistä ja tulkinnoista ovat herättäneet paljon keskustelua, kritiikkiä ja vaihtoehtoisia tulkintoja.39 Tarkastelemalla ilmiötä hieman etäämmältä voidaan huomata, että vaalikoneaineistot ovat innoittaneet vilkasta avointa tutkimusta, kun aineistot ovat lähtökohtaisesti avoimia ja osallistujat julkaisevat tutkimuksensa, kritiikkinsä ja menetelmänsä avoimesti.
Politiikan sisältöjä tarkastelevia tutkimuksia edustavat esimerkiksi Jouni Tuomiston edellä mainitun artikkelin jatkoksi tehdyt analyysit poikkipuolue- ja jokapuoluehallituksista. Ensin mainittu hallituskokoonpano muodostuu puolueiden poikki niistä kansanedustajista, jotka kuuluvat vastausvaihtoehtojen enemistön kannalle. Kukin edustaja saa samanmielisyyspisteet enemmistömielisyydestään. Hallitusohjelma muodostuu niistä vaalikonekysymyksistä, jotka ehdottavat jotakin muutosta nykyiseen ja ehdotusta on kannattanut selkeä enemmistö.40
Jokapuoluehallitus perustuu muuten samaan ajatukseen kuin poikkipuoluehallitus, mutta sen muodostamisessa huomioidaan puoluekurin vaikutus. Puolueen enemmistön kanta saa tällöin puolueen kaikkien edustajien äänen taakseen. Tällöin jotkin puolueita sisäisesti tasaisesti jakavista kysymyksistä voivat ratketa eduskunnan tasolla huomattavasti selkeämmin luvuin, ja niin hallitusohjelmastakin tulee erilainen.
Data ja demokratia
Tämän artikkelin taustoittamiseksi tutustuin hyvään pintaraapaisuun monipuolisia tutkimuksia ja aineistoja, jotka paljastavat ainakin sen, että politiikan tutkijoilta ei puutu aineistoja, eikä luovuutta ja uutta ajattelua menetelmävalintojen suhteen. Sen sijaan kehittymisen varaa lienee varmasti enemmän menetelmien tieteellisessä pätevyydessä ja teknisessä sovellettavuudessa. Ohjelmointitaitoiset voivat hyödyntää nopeasti valmiita koodikirjastoja enemmän tai vähemmän soveltuviin aineistoihin tai kehittää omia ratkaisujaan, mutta tulkintojen validiteetin arvioiminen jää joko dokumentaation, ei-ohjelmointitaitoisille suunnattujen vastaavien työkalujen saatavuuden tai toisten ohjelmointitaitoisten samojen aiheiden tutkijoiden aktiivisuuden varaan. Kun vielä ajan henki suosii nopeaa ja näyttävää tutkimustulosten viestintää, tieteellinen laatu voi joutua sivulliseksi uhriksi. Hyvä esimerkki ei-ohjelmistotaitoisille suunnatusta data-aineistojen tutkimustyökalusta on kuitenkin Kielipankin Korp-käyttöliittymä, jolla voi analysoida suuria tekstiaineistoja.41 Tämänkaltaisia työkaluja toivoisi näkevän tulevaisuudessa myös politiikan tutkimuksen alueella. Se ei poista tutkijoiden tarvetta menetelmien ymmärtämiseen, mutta voi luoda siltaa ohjelmointiin ja eri substanssikysymyksiin erikoistuneiden tieteenharjoittajien välille.
Toinen erityisen mielenkiintoinen kysymys on vaalikone- ja sosiaalisen median aineistojen todistusvoima kansalaisten arvojen ja julkisen mielipiteen suhteen. On parhaillaan eri tutkijoiden ja tutkimushankkeiden työn alla ratkoa menetelmiin liittyviä teknisiä ongelmia siitä kuinka vaalikonedatasta ja sosiaalisen median keskusteluista jalostetaan niin sanottua kansan tahtoa, joka voitaisiin ilmaista esimerkiksi hallitusohjelman tai yksittäisten lakien muodossa. Aineistolähtöisyyden vastavoimaksi asettuu kuitenkin luotettavuuteen ja edustavuuteen liittyvät kysymykset. Syrjiikö digikuilu vielä 2010-luvun lopulla joitakin ryhmiä tai ovat vaalikoneet tai sosiaalinen media itsessään tai niitä ylläpitävät mediatalot epädemokraattista vääristymää aiheuttava tekijä? Olisi itse asiassa mielenkiintoista paneutua siihen, kumpaa ihmiset vierastavat enemmän -äänestämistä vai verkkoa poliittisen mielipiteenilmaisun välineenä. Jos verkkoa ei nähdä ongelmana ja siirrytään pohtimaan aineistojen täyttä potentiaalia demokratian kannalta, voidaan asetelma pelkistää vaikka seuraavanlaiseen kysymykseen: kumpi on demokraattisempaa, johtaa hallitusohjelma suoraan vaalikoneen (tai kahden, Helsingin Sanomat ja Yle, synteesistä) yli 200 000 vastaajan otoksesta vai että vajaan kolmen miljoonan äänestäjän tahto pelkistetään 200 edustajaan, joista vain pieni osa osallistuu eturyhmien edustajien ja korkeiden virkamiesten kanssa neuvottelemaan ja kirjoittamaan vaalikauden tavoitteita? Nyt kun aineistoja alkaa olla tarjolla ja menetelmät kehittyvät, olisi älyllistä epärehellisyyttä hyödyntää niitä vain puolueiden tai edustuksellisuuden ongelmien ratkaisemiseen ja jättää taustalla piilevä laajempi demokratian toimintaedellytysten ongelma huomiotta.
Tämä artikkeli on kirjoitettu alkujaan keväällä 2016 opintosuoritukseksi valtio-opin syventävien menetelmien kurssille. Sitä on päivitetty julkaisun yhteydessä vähäisissä määrin. Artikkelista on julkaistu myös tiivistelmä Alusta!-verkkolehdessä.
Lähdeluettelo
Datavaalit (2016), <http://www.datavaalit.fi/>
Datavaalit (2016b), <https://github.com/avoindata>
Digivaalit (2015), <https://www.hiit.fi/digivaalit-2015>
Digivaalit (2016) <https://rajapinta.files.wordpress.com/2016/04/dv2015-posteri-verkosto-lores.pdf>
Eranti, Veikko & Ylä-Anttila Tuukka (2016) <http://www.slideshare.net/tuylaant/using-topic-modeling-to-study-everyday-civic-talk-and-protopolitical-engagements>
Haakana, Kari (2011) <http://yle.fi/aihe/artikkeli/2011/05/16/vuoden-2011-vaalikonetiedot-nyt-avoimena-datana>
Haakana, Kari (2012) <http://yle.fi/aihe/artikkeli/2012/01/13/presidentinvaalien-vaalikoneen-kayttajien-vastaukset-avoimena-datana>
Helsingin Sanomat (2012) <http://www.hs.fi/politiikka/a1305606343277>
Ted Holmes (2005) <http://simplyted.blogspot.fi/2005/12/how-to-visualize-data.html>
Kekkonen, Arto (2016) <https://rajapinta.files.wordpress.com/2016/04/dv2015-posteri-kekkonen-lores.pdf>
Laaksonen, Salla-Maaria (2015) <https://rajapinta.co/2015/04/19/alustavia-analyyseja-eduskuntavaalipohinasta-sosiaalisessa-mediassa/>
Laaksonen, Salla-Maaria (2015b) <https://rajapinta.co/2015/09/17/verkon-agendaa-asettamassa-vaikuttajaindeksilaskelmia-digivaalit-2015-projektista/>
Laaksonen, Salla-Maaria (2015c) <https://rajapinta.co/2015/06/04/suomi24-data-science-hackathon-results-and-afterthoughts/>
Laaksonen, Salla-Maaria (2016a) <https://rajapinta.files.wordpress.com/2016/04/digivaalit_finalseminar-pptx.pdf>
Laaksonen, Salla-Maaria (2016b), <https://rajapinta.co/2016/05/02/sosiaalinen-media-tutkimusaineiston-hankala-aarrearkku/>
Lagus, Krista, Mika Pantzar, Minna Ruckenstein ja Marjoriikka Ylisiurua (2016), Suomi24 -Muodonantoa aineistolle. <http://blogs.helsinki.fi/citizenmindscapes/>
Lahti, Leo (2012a), Kunnallisvaaliehdokkaiden aktiivisuus sosiaalisessa mediassa: puolueiden vertailua. <https://louhos.wordpress.com/2012/10/26/kunnallisvaaliehdokkaiden-aktiivisuus-sosiaalisessa-mediassa-puolueiden-vertailua/>
Lahti, Leo (2012b), Kunnallisvaalien vertailukelpoiset ehdokasdatat CSV-taulukkoina: 2004 / 2008 / 2012 <https://louhos.wordpress.com/2012/10/05/kunnallisvaalien-vertailukelpoiset-ehdokasdatat-csv-taulukkoina-2004-2008-2012/>
Lahti, Leo (2012c), Datavaalit: Oikeusministeriön vaalidatat sorvattu auki. <https://louhos.wordpress.com/2012/09/28/datavaalit-oikeusministerion-vaalitulosdata-sorvattu-auki/>
Lahti, Leo (2012d), Helsingin Sanomien avoin vaalikonedata: osa2. <https://louhos.wordpress.com/2012/02/05/helsingin-sanomien-avoin-vaalikonedata-osa2/>
Lahti, Leo (2013), Kunnallisvaalit sosiaalisessa mediassa. <https://louhos.wordpress.com/2013/01/26/kunnallisvaalit-sosiaalisessa-mediassa/>
Leppänen, Martti (2011a) http://www2.hs.fi/extrat/kotimaa/puoluekentta/
Leppänen, Martti (2011b), Puoluekenttä. <http://puoluekentta.tstm.info/>
MTV (2006), Presidentinvaalit 2006: ehdokkaiden vastaukset MTV3:n vaalikoneeseen. Yhteiskuntatieteellinen tietoarkisto [jakaja]. <http://urn.fi/urn:nbn:fi:fsd:T-FSD2127>
Marttila Mari (2016) <https://rajapinta.files.wordpress.com/2016/04/dv2015-posteri-marttila-lores.pdf] >
Mäkinen, Esa (2011a) <http://blogit.hs.fi/hsnext/hs-julkaisee-vaalikoneensa-avoimena-tietona-ennen-vaaleja >
Mäkinen, Esa (2011b) <http://blogit.hs.fi/hsnext/hsn-vaalikone-on-nyt-avointa-tietoa>
Mäkinen, Esa (2011c) <http://blogit.hs.fi/hsnext/vaalikonedata-avoimeksi-kristilliset-eniten-avioliitossa>
Mäkinen, Esa (2011d) <http://blogit.hs.fi/hsnext/15-uusiokayttoa-hsn-vaalikonedatalle-viikossa>
Mäkinen, Esa (2012a) <http://blogit.hs.fi/hsnext/helsingin-sanomat-julkaisee-vaalikoneen-tiedot-avoimena-rajapintana>
Mäkinen, Esa (2012b) <http://blogit.hs.fi/hsnext/nain-kuntalaiset-yhdistaisivat-kotikuntansa-kuntakoneen-vastaukset-avodatana>
Mäkinen, Esa (2012c) <http://blogit.hs.fi/hsnext/hs-open-tapahtumissa-luodaan-tietojournalismia>
Mäkinen, Esa (2015) <http://www.hs.fi/politiikka/a1305929269692>
Parkkinen, Juuso (2012) <https://louhos.wordpress.com/2012/01/06/kenesta-seuraava-presidentti-ennusta-itse-hsn-vaalikonedatan-avulla/>
Poikola, Antti, Kola, Petri & Hintikka, Kari A. (2010), Julkinen data. johdatus tietovarantojen avaamiseen. Helsinki: Liikenne- ja viestintäministeriö.
Pollock, Rufus (2014) <http://blog.okfn.org/2014/09/30/why-the-open-definition-matters-for-open-data-quality-compatibility-and-simplicity/>
Quora (2016), <https://www.quora.com/How-much-data-is-Big-Data>
Rouse, Margaret (2008) <http://searchstorage.techtarget.com/definition/How-many-bytes-for>
Sairanen, Heikki (2016)[ http://sairanen.org/wordpress/blog/2016/04/24/poliittiset-akselit/](http://sairanen.org/wordpress/blog/2016/04/24/poliittiset-akselit/)
Stack Overflow (2016), <http://stackoverflow.com/questions/14045056/how-big-data-is-bigdata>
Tuokko, Mari (2015) <https://rajapinta.co/2015/05/25/vaalit2015-muutama-sana-olohuonetentista-ja-twitterista/>
Tuokko, Mari (2016) <https://rajapinta.co/2016/03/10/digivaalit-2015-ehdokkaiden-ja-kansalaisten-vuorovaikutus-sosiaalisessa-mediassa-vaalikampanjoinnin-aikana-tyhjyyteen-huutelua-vai-merkityksellista-dialogia/>
Tuomisto, Jouni ym. (2011a) <http://fi.opasnet.org/fi/Kansanedustajien_arvot>
Tuomisto, Jouni ym. (2011b) <http://fi.opasnet.org/fi/Poikkipuoluehallitus>
Tuomisto, Jouni ym. (2011c) <http://fi.opasnet.org/fi/Jokapuoluehallitus>
Törmänen, Juha (2011)[ http://peili.kirkas.info/archive/hsvaalikone11/kartta/](http://peili.kirkas.info/archive/hsvaalikone11/kartta/)
Törmänen, Juha (2012)[ http://peili.kirkas.info/archive/hsvaalikone12/](http://peili.kirkas.info/archive/hsvaalikone12/)
Valtiontalouden tarkastusvirasto (2016), <http://www.vaalirahoitus.fi/>
Wikipedia: Big data (2016), <https://en.wikipedia.org/w/index.php?title=Big_data&oldid=722833400>
Yhteiskuntatieteellinen tietoarkisto (2016), <http://www.fsd.uta.fi/fi/aineistot/taustatietoa/vaalidataa.html>
Yle (2012) <http://yle.fi/uutiset/nyt_sita_saa_vaalikonedataa/6331306>
Yle (2015) <http://yle.fi/uutiset/yle_julkaisee_vaalikoneen_vastaukset_avoimena_datana/7869597>
Yle (2016) <http://yle.fi/aihe/artikkeli/2016/05/18/ylen-sisaltoja-tarjolla-avoimena-datana>
Pamela Vagata, Kevin Wilfong 2014 <https://code.facebook.com/posts/229861827208629/scaling-the-facebook-data-warehouse-to-300-pb/>
Xu, Wei, (2016) Twitter API Tutorial <http://socialmedia-class.org/twittertutorial.html>
Tekstin sisäiset viitteet
-
Poikola, Kola ja Hintikka 2010, 13-14. ↩︎
-
Holmes 2005; Rouse 2008; Vagata ja Wilfong 2014. ↩︎
-
Quora 2016; Stack Overflow 2016; Wikipedia: Big data 2016. ↩︎
-
Emt. ↩︎
-
Poikola ym. 2010; Pollock 2014. ↩︎
-
Lagus, Pantzar, Ruckenstein & Ylisiurua 2016. ↩︎
-
Laaksonen 2016b. ↩︎
-
Xu 2016. ↩︎
-
Wu 2015. ↩︎
-
Datavaalit 2016. ↩︎
-
Lahti 2012a; Lahti 2013. ↩︎
-
Twiittien tarkka määrä jää epäselväksi, sillä Rajapinta-blogissa puhutaan koko aineiston osalta Facebookin kanssa yhdessä yli 1,5 miljoonasta viestistä, mutta pelkkien Twiittien osalta johdonmukaisin tulkinta on erikseen mainittu noin yli 200 000 twiitin aineisto. Kts. Digivaalit 2016. https://rajapinta.co/2016/04/07/digivaalit-2015-paatosseminaarin-materiaali/ ↩︎
-
Digivaalit 2015; Laaksonen 2016a; Laaksonen 2016b. ↩︎
-
Digivaalit 2016. ↩︎
-
Marttila 2016. ↩︎
-
Kekkonen 2016. ↩︎
-
Tuokko 2016. ↩︎
-
Tuokko 2015. ↩︎
-
Laaksonen 2015b. ↩︎
-
Lagus ym. 2016. ↩︎
-
Emt., 43. ↩︎
-
Eranti ja Ylä-Anttila 2016. ↩︎
-
Laaksonen 2015c. ↩︎
-
Valtiontalouden tarkastusvirasto 2016. ↩︎
-
Datavaalit 2016b; Lahti 2012b; Lahti 2012c. ↩︎
-
Haakana 2011; Haakana 2012; Mäkinen 2011a; Mäkinen 2011b; Mäkinen 2015; Yle 2012; Yle 2016. ↩︎
-
Mäkinen 2011c. ↩︎
-
MTV 2006. ↩︎
-
Yhteiskuntatieteellinen tietoarkisto 2016. ↩︎
-
Mäkinen 2015; Yle 2015. ↩︎
-
Mäkinen 2011c. ↩︎
-
Haakana 2012. ↩︎
-
Mäkinen 2012a. ↩︎
-
Parkkinen 2012. ↩︎
-
Lahti 2012d. ↩︎
-
Mäkinen 2012b. ↩︎
-
Tuomisto ym. 2011a. ↩︎
-
Kts. esim. Helsingin Sanomat 2012; Leppänen 2011a; Leppänen 2011b; Mäkinen 2012c; Sairanen 2016; Törmänen 2011; Törmänen 2012. ↩︎
-
Mäkinen 2011d. ↩︎
-
Tuomisto ym. 2011b; Tuomisto ym. 2011c. ↩︎
-
Lagus ym. 2016. ↩︎