Yleistä
Turun kaupunki avasi syksyllä 2020 pienaluetilastoja, jotka antavat jo ennestään saatavilla olleiden postinumeroaluekohtaisten tilastojen ohella mahdollisuuden tarkastella Turun kaupungin alueita hienojakoisemmin kuin aiemmin on ollut mahdollista.
Tietoa on kirjoitushetkellä saatavissa Turussa sijaitsevista rakennuksista, asunnoista ja vapaa-ajanasunnoista (esim. hallintaperuste, valmistumisvuosi, kerrosala), muuttoliikkeestä ja väestönmuutoksista (esim. syntymät, kuolemat, muutto kuntaan ja kunnasta pois) ja väestörakenteesta (asukkaiden ikä, sukupuoli, kieli, veronalaiset tulot).
Ainakin toistaiseksi Turun kaupunki tarjoaa valmiissa muodossa ainoastaan pienaluetilastoja sekä koko kaupungin kattavia tilastoja. Kaupunkitasoista dataa on saanut jo pitkään Tilastokeskuksen sivuilta, joten varsinainen uutuusarvo liittyykin nimenomaan pienaluetilastoihin. Pienaluetilastoista voidaan tarvittaessa aggregoida ylemmän tason alueita kuten tilastoalueita ja suuralueita.
Pienaluetilastojen sisältämä data on Tilastokeskuksen asettamien ehtojen vuoksi rajattu siten, että tietoja ei julkisteta niiltä alueilta, joilla asuu alle 100 henkilöä tai alle 100 asuntokuntaa / perhettä, käy töissä alle 100 henkilöä tai joilla sijaitsee alle 10 asuinrakennusta.
Suurin osa julkaistuista pienaluedatoista on itse asiassa aikasarjadataa, joten mielenkiintoisten ajallisten muutosten tarkastelu on mahdollista. Ilmiselvästi mielenkiinnon kohteena olevien alueiden tulisi kuitenkin pysyä suhteellisen muuttumattomina, jotta vertailu olisi mielekästä. Tilastokeskuksen sivuilta löytyvän artikkelin (Tammilehto-Luode, 2009) mukaan “[k]untien sisäinen aluejako on syntynyt kuntien omien tarpeiden pohjalta”.
Turussakin kaupunki on kehittynyt 10 vuoden aikana, uusia asuinalueita on rakennettu ja väkilukukin on kasvanut yli 10 000 asukkaalla. Pienalueiden rajat saattavat muuttua samalla kun kaupunki kasvaa ja kehittyy. Aluejakojen pysyvyys ei tietenkään ole vakio laajemmassakaan mittakaavassa, sillä kuntaliitoksia ja kuntarajojen uudelleenvetoja tapahtuu melkein vuosittain (ks. Tilastokeskuksen luokitustiedotteet), postinumeroalueita muutetaan (ks. Postin sivut) ja maakuntien rajojakin vedetään toisinaan uudelleen.
Pienaluetilastojen yhdistäminen karttatietoaineistoon vaatii enemmän manuaalista työtä kuin esimerkiksi Tilastokeskuksen sivuilta pxweb-paketilla ladatun tiedon visualisointi geofi-pakettia käyttämällä. Tähän saadaan tulevaisuudessa mahdollisesti muutos, mutta tämän blogitekstin on tarkoitus demonstroida nykyhetkessä, kuinka helppoa datan visualisointi on ilman erikoistuneita pakettejakin.
Pienaluetilastojen lataaminen ja visualisointi
# px-muotoisen datan lukemiseen tarvittava paketti
library(pxR)
# Datan käsittelyyn tarvittavat tidyverse-paketit
library(dplyr)
library(tidyr)
# Geospatiaalisen datan käsittelyyn tarvittavat paketit
library(sf)
library(ggplot2)Käytän tässä kirjoituksessa pxR-pakettia, sillä ainakin toistaiseksi Turun kaupunki toimittaa pienaluetilastonsa px-muodossa. Px-tiedostomuoto on moniulotteisen tilastotaulukon eli kuution tallennusformaatti, josta voi saada jonkinlaista lisätietoa esimerkiksi vuonna 2008 julkaistusta käsikirjasta tai Ruotsin SCB:n tiedostomuodon määrittelystä. Px-dataa voidaan Windows-koneilla käsitellä erillisellä PxWin-ohjelmistolla, mutta Macin tai Linuxin käyttäjille tämä ei valitettavasti ole vaihtoehto.
pxR-paketti ei lue pysty lukemaan kaikkia tarjolla olevia .px-muodossa olevia tietoaineistoja, mutta toivottavasti paketin kehitystyö korjaa ongelman tulevaisuudessa tai avointa dataa tarjotaan jatkossa toisenlaisessa muodossa.
# URL lähde: https://www.avoindata.fi/data/fi/dataset/turun-kaupungin-pienaluetilastoja
url_data <- "https://dev.turku.fi/datasets/pienaluetilastot/turku-asunnot-r03e.px"
# pxR-paketin standardinomainen tapa lukea Tilastokeskuksen px-dataa ei toimi:
# read.px(filename = url)
#Error in scan(tc, na.strings = na.strings, quote = NULL, quiet = TRUE) :
# scan() expected 'a real', got '..'
# Käytetään argumenttia na.strings = c(".."), jolloin data voidaan lukea
px_data <- read.px(url_data, na.strings = c(".."))Vuoden 2008 PC-Axis-tiedostomuodon käsikirjasta voidaan lukea, että pistekoodi “..” tarkoittaa tietoa, jota ei ole saatu, joka on epävarmaa tai joka on salassapitosäännön alaista. Kuten aiemminkin mainittiin, Turun kaupunki on rajannut julkaisemiensa aineistojen laajuutta. Puuttuvan tiedon voikin suurimmalti osalti selittää salassapitosäännöksen mukaisella rajauksella, mistä johtuen kahden pisteen pistekoodi lienee tullut valituksi.
Tarkastellaan seuraavaksi lataamamme px_data-objektin sisältöä:
# px_data-objektin sisältämät avainsanat
names(px_data)
## [1] "AXIS.VERSION" "CHARSET" "CODEPAGE" "CODES" "CODES.sv."
## [6] "CONTACT" "CONTACT.sv." "CONTENTS" "CONTENTS.sv." "CONTVARIABLE"
## [11] "CONTVARIABLE.sv." "COPYRIGHT" "CREATION.DATE" "DATA" "DECIMALS"
## [16] "DESCRIPTION" "DESCRIPTION.sv." "DESCRIPTIONDEFAULT" "DOMAIN" "DOMAIN.sv."
## [21] "HEADING" "HEADING.sv." "LANGUAGE" "LANGUAGES" "LAST.UPDATED"
## [26] "MATRIX" "NOTE" "NOTE.sv." "SHOWDECIMALS" "SOURCE"
## [31] "SOURCE.sv." "STUB" "STUB.sv." "SUBJECT.AREA" "SUBJECT.AREA.sv."
## [36] "SUBJECT.CODE" "TIMEVAL" "TIMEVAL.sv." "TITLE" "TITLE.sv."
## [41] "UNITS" "UNITS.sv." "VALUES" "VALUES.sv." "VARIABLE.TYPE"
## [46] "VARIABLE.TYPE.sv."
# px_data-objektin luokka
class(px_data)
# [1] "px"
# px_data-objektin rakenne: Tulostaa erittäin pitkän listan tietoja, jota en toista tässä esimerkissä
str(px_data)
# Muoto, jossa px_data-objektin tiedot on tallennettu
typeof(px_data)
# [1] "list"Huomataan, että suurin osa px_data-objektin sisällöstä on erilaista metatietoa, joka on tietojen raportoinnin kannalta yleensä hyvä ottaa huomioon. Olennaisin tieto löytyy kuitenkin jo otsikosta: Asunnot osa-alueittain huoneistotyypin ja hallintaperusteen mukaan vuosina 2015-2019. Numeerisen tilastotiedon tarkastelun ja visualisoinnin kannalta kiinnostavin sisältö löytyy DATA-avainsanan takaa. DATA-elementti sisältää vastaavasti data.framen nimeltä value, josta olemme kiinnostuneita.
# Muodostetaan uusi muuttuja turku_data px_data-objektin sisältämästä data.framesta
turku_data <- px_data$DATA$value
# px_data -objektin kuvauksen tallentaminen voi olla hyödyllistä myöhemmin
turku_data_otsikko <- px_data$DESCRIPTION$value
turku_data_otsikko## [1] "R03E Asunnot osa-alueittain huoneistotyypin ja hallintaperusteen mukaan 31.12, 2015-2019"dim(turku_data)## [1] 50435 5summary(turku_data)## Hallintaperuste Huoneistotyyppi
## Hallintaperusteet yhteensä :7205 Huoneistotyypit yhteensä: 4585
## Omistaa talon :7205 1h+kk/kt : 4585
## Omistaa asunnon osakkeet :7205 1h+k : 4585
## Arava- tai korkotukivuokra-asunto :7205 2h+kk/kt : 4585
## Muu vuokra-asunto :7205 2h+k : 4585
## Asumisoikeusasunnot :7205 3h+k/kk/kt : 4585
## Muu tai tuntematon hallintaperuste:7205 (Other) :22925
## Vuosi Osa.alue value
## 2015:10087 853 Turku : 385 Min. : 0.00
## 2016:10087 853101001 Rauhankatu VII : 385 1st Qu.: 0.00
## 2017:10087 853101002 Ursininkatu pohj. : 385 Median : 2.00
## 2018:10087 853101003 Ursininkatu et. : 385 Mean : 99.96
## 2019:10087 853101004 Kristiinankatu et. : 385 3rd Qu.: 23.00
## 853101005 Kristiinankatu pohj.: 385 Max. :119908.00
## (Other) :48125 NA's :4158dim-komennon tulos kertoo, että data.framessa on 50435 riviä ja 5 saraketta. Summaryn tulkitseminen on tässä yhteydessä hieman hankalampaa, mutta käytännössä luvut kertovat, kuinka monta kertaa kukin uniikki rivi esiintyy tässä pitkässä muodossa olevassa taulukossa. Numeroista ei siis voi tehdä päätelmiä minkään ryhmän jäsenten lukumäärästä vaan ennemmin siitä, kuinka monta kertaa kukin muuttuja esiintyy taulukossa.
Olemme tällä kertaa kiinnostuneita eri pienalueiden tiedoista. Visualisoinnin yksinkertaistamiseksi tarkastelemme omistusasujien määrän suhdetta kaikkiin asumismuotoihin, joten valitsemme siis Hallintaperuste-sarakkeesta “Hallintaperusteet yhteensä”, “Omistaa talon” ja “Omistaa asunnon osakkeet”. Huoneistotyypin osalta emme tee erottelua. Osa.alue- ja Vuosi-sarakkeista voimme ottaa kaikki tiedot, sillä tarvittavat rajaukset voidaan tehdä samalla kun tilastotietoja yhdistetään paikkatietoon.
Pelkästään pienalueita tarkasteltaessa uuden area_code -sarakkeen luominen ei ole välttämätöntä, sillä pienaluedatan sisältävät tietoaineistot sekä pienalueiden paikkatietoaineistot käyttävät toisiaan vastaavia nimikkeitä. Muiden aineistojen kanssa toimiessa on kuitenkin hyödyllistä, että numeromuodossa oleva aluekoodi ja alueen nimi erotellaan erillisiksi sarakkeiksi.
turku_data2 <- turku_data %>%
filter(Hallintaperuste %in% c("Hallintaperusteet yhteensä", "Omistaa talon", "Omistaa asunnon osakkeet"), Huoneistotyyppi == "Huoneistotyypit yhteensä")
summary(turku_data2)## Hallintaperuste Huoneistotyyppi
## Hallintaperusteet yhteensä :655 Huoneistotyypit yhteensä:1965
## Omistaa talon :655 1h+kk/kt : 0
## Omistaa asunnon osakkeet :655 1h+k : 0
## Arava- tai korkotukivuokra-asunto : 0 2h+kk/kt : 0
## Muu vuokra-asunto : 0 2h+k : 0
## Asumisoikeusasunnot : 0 3h+k/kk/kt : 0
## Muu tai tuntematon hallintaperuste: 0 (Other) : 0
## Vuosi Osa.alue value
## 2015:393 853 Turku : 15 Min. : 0.0
## 2016:393 853101001 Rauhankatu VII : 15 1st Qu.: 40.5
## 2017:393 853101002 Ursininkatu pohj. : 15 Median : 161.0
## 2018:393 853101003 Ursininkatu et. : 15 Mean : 918.0
## 2019:393 853101004 Kristiinankatu et. : 15 3rd Qu.: 593.5
## 853101005 Kristiinankatu pohj.: 15 Max. :119908.0
## (Other) :1875 NA's :162# Luodaan uusi muuttuja area_code poistamalla Osa.alue-muuttujasta aakkoset, välimerkit ja välilyönnit
turku_data2 <- turku_data2 %>%
dplyr::mutate(area_code = gsub("[[:alpha:]]*[[:punct:]]*[[:blank:]]*", "", turku_data2$Osa.alue))
# Muutetaan pitkä datamuoto leveäksi
turku_data2 <- turku_data2 %>%
tidyr::pivot_wider(id_cols = c("Vuosi", "area_code"), names_from = "Hallintaperuste", values_from = "value")
# Siivotaan sarakkeita käytettävämpään muotoon
turku_data2 <- turku_data2 %>%
dplyr::mutate(omistusasunto = `Omistaa talon` + `Omistaa asunnon osakkeet`) %>%
dplyr::mutate(muu_asumismuoto = `Hallintaperusteet yhteensä` - omistusasunto) %>%
dplyr::rename(hallintaperusteet_yhteensa = `Hallintaperusteet yhteensä`) %>%
dplyr::select(-c(`Omistaa talon`, `Omistaa asunnon osakkeet`))Seuraavaksi yhdistämme datatiedot geospatiaaliseen dataan käyttämällä sf-pakettia sekä visualisointiin ggplot2-pakettia.
url_geo <- "http://dev.turku.fi/datasets/aluejaot/pienalueet-4326.geojson"
turku_pienalueet <- sf::st_read(dsn = url_geo)## Reading layer `aj_osa-alue_20200415_area' from data source `http://dev.turku.fi/datasets/aluejaot/pienalueet-4326.geojson' using driver `GeoJSON'
## Simple feature collection with 129 features and 1 field
## geometry type: POLYGON
## dimension: XY
## bbox: xmin: 22.06614 ymin: 60.33351 xmax: 22.45816 ymax: 60.73729
## geographic CRS: WGS 84turku_pienalueet <- turku_pienalueet %>%
mutate(area_code = gsub("[[:alpha:]]*[[:punct:]]*[[:blank:]]*", "", turku_pienalueet$id))
dat <- dplyr::left_join(turku_pienalueet, turku_data2, by = "area_code")Visualisoidaan omistusasujien osuus suhteessa kaikkiin asumismuotoihin:
viz_dat <- dat %>%
filter(Vuosi == 2019)
ggplot(viz_dat) +
geom_sf(aes(fill = omistusasunto / hallintaperusteet_yhteensa), color = alpha("white", 1/3)) +
labs(fill="Omistusasujien osuus 2019")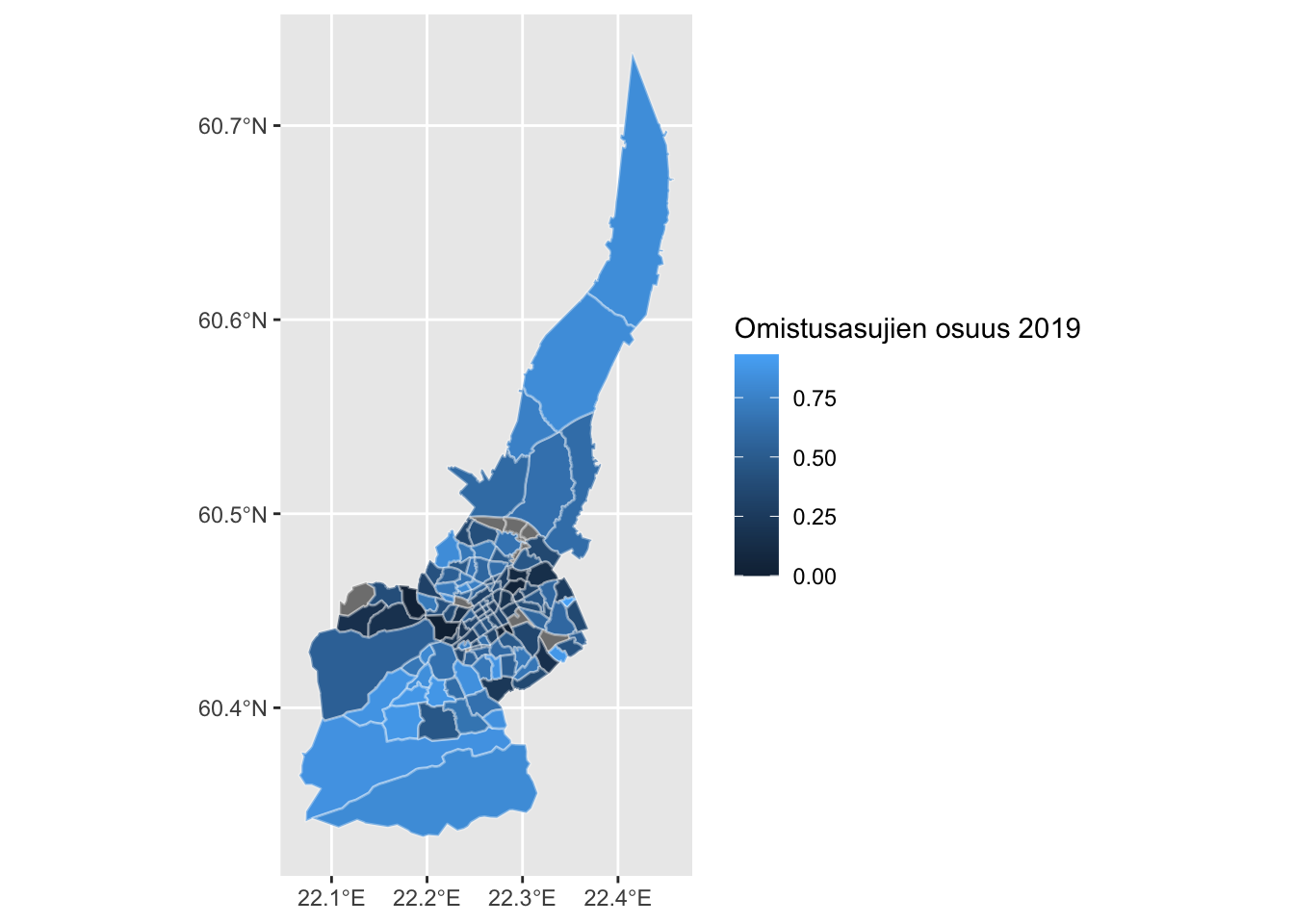
Kuten huomataan, osasta pienalueista data puuttuu kokonaan. Pienalueita käytettäessä kartasta tulee helposti turhan yksityiskohtaista piiperrystä. Eräs ratkaisu tähän olisi tehdä pienaluekuvista kartogrammi (esim. cartogram-pakettia käyttämällä), jossa väkirikkaammat pienalueet piirrettäisiin suhteellisesti suurempina kuin harvaan asutummat pienalueet. Tällöin kartan maantieteellinen vastaavuus kuitenkin vääristyisi ja “karttakuva” muuttuisi entistä abstraktimman tason visualisoinniksi.
Toinen ratkaisu on muodostaa pienaluetilastoista suurempia alueita ryhmittelemällä ne uudelleen.
Pienalueiden uudelleenryhmittely tilastoalueiksi ja suuralueiksi
Turku voidaan jakaa 9 suuralueeseen, 45 tilastoalueesta ja 129 pienalueesta. Jokainen suuralue sisältää useamman tilastoalueen ja useimmat tilastoalueet sisältävät useita pienalueita. Joidenkin ilmeisesti harvaan asuttujen alueiden tapauksessa tilastoalueet sisältävät ainoastaan yhden pienalueen.
Useimmat aiemmin muodostetut aluekoodit muodostuvat 9 numerosta, esimerkkinä “853943130 Saramäki - Paimala”. 853 on Turun kaupungin kuntakoodi, 9 on Maaria-Paattisen suuralueen numero, 43 on Etelä-Maarian tilastoalueen numero ja 130 on Saramäki-Paimalan pienaluekoodi. Koska numerosarja on kaikkien tapausten osalta saman pituinen ja eri alueita merkitsevät numerot ovat aina samassa kohdassa, koodi pystytään helposti purkamaan osiin:
dat$suuralue <- substring(dat$area_code, first = 4, last = 4)
dat$tilastoalue <- substring(dat$area_code, first = 5, last = 6)
dat$pienalue <- substring(dat$area_code, first = 7, last = 9)dat_suuralue <- sf::st_make_valid(dat) %>%
dplyr::filter(Vuosi == 2019) %>%
dplyr::group_by(suuralue) %>%
dplyr::summarise(hallintaperusteet_yhteensa = sum(hallintaperusteet_yhteensa, na.rm = TRUE),
omistusasunto = sum(omistusasunto, na.rm = TRUE), muu_asumismuoto = sum(muu_asumismuoto, na.rm = TRUE))
dat_tilastoalue <- sf::st_make_valid(dat) %>%
dplyr::filter(Vuosi == 2019) %>%
dplyr::group_by(tilastoalue) %>%
dplyr::summarise(hallintaperusteet_yhteensa = sum(hallintaperusteet_yhteensa, na.rm = TRUE), omistusasunto = sum(omistusasunto, na.rm = TRUE), muu_asumismuoto = sum(muu_asumismuoto, na.rm = TRUE)) Lopuksi visualisoidaan:
ggplot(dat_suuralue) +
geom_sf(aes(fill = omistusasunto / hallintaperusteet_yhteensa), color = alpha("white", 1/3)) +
labs(fill="Omistusasujien osuus 2019")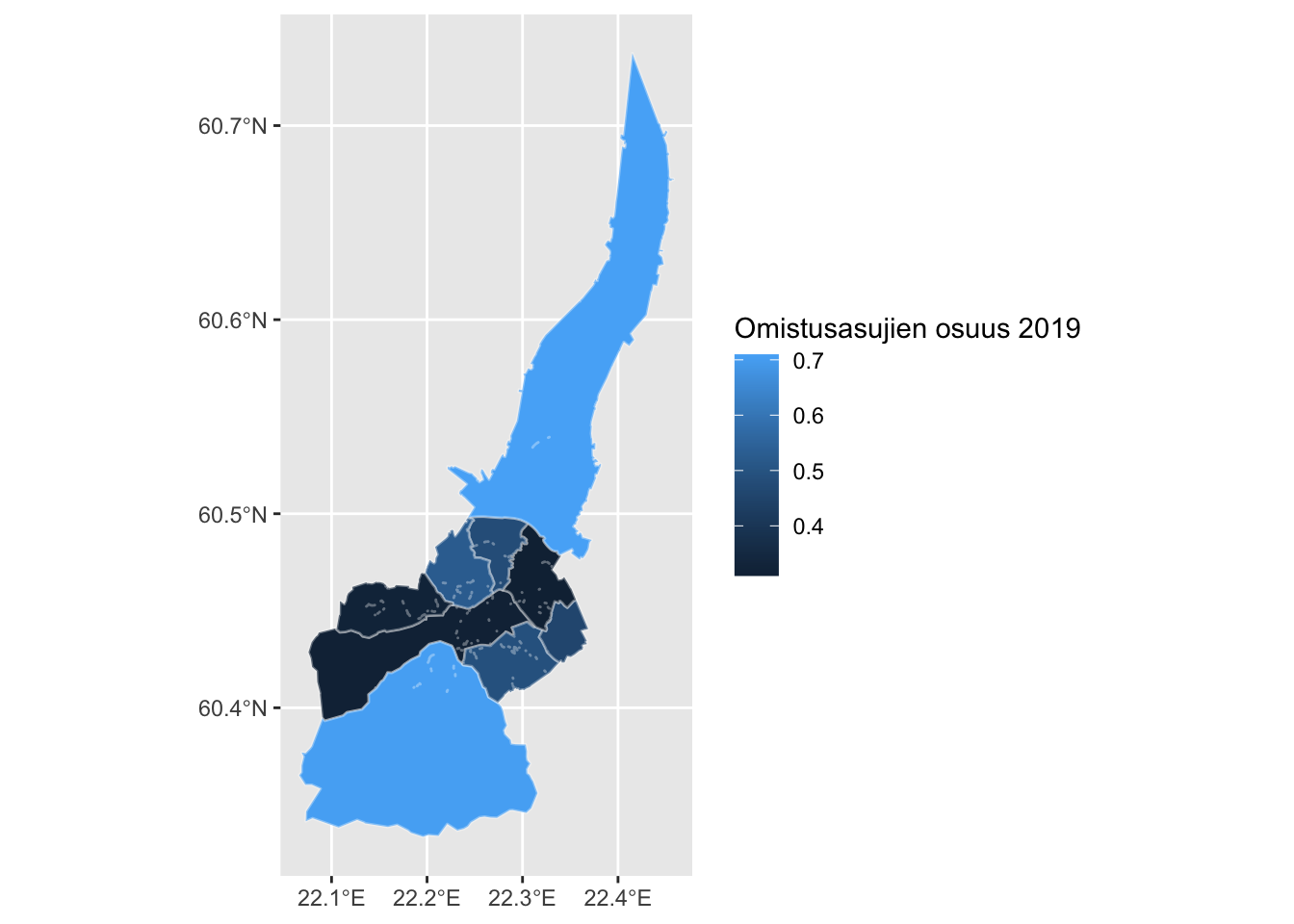
ggplot(dat_tilastoalue) +
geom_sf(aes(fill = omistusasunto / hallintaperusteet_yhteensa), color = alpha("white", 1/3)) +
labs(fill="Omistusasujien osuus 2019")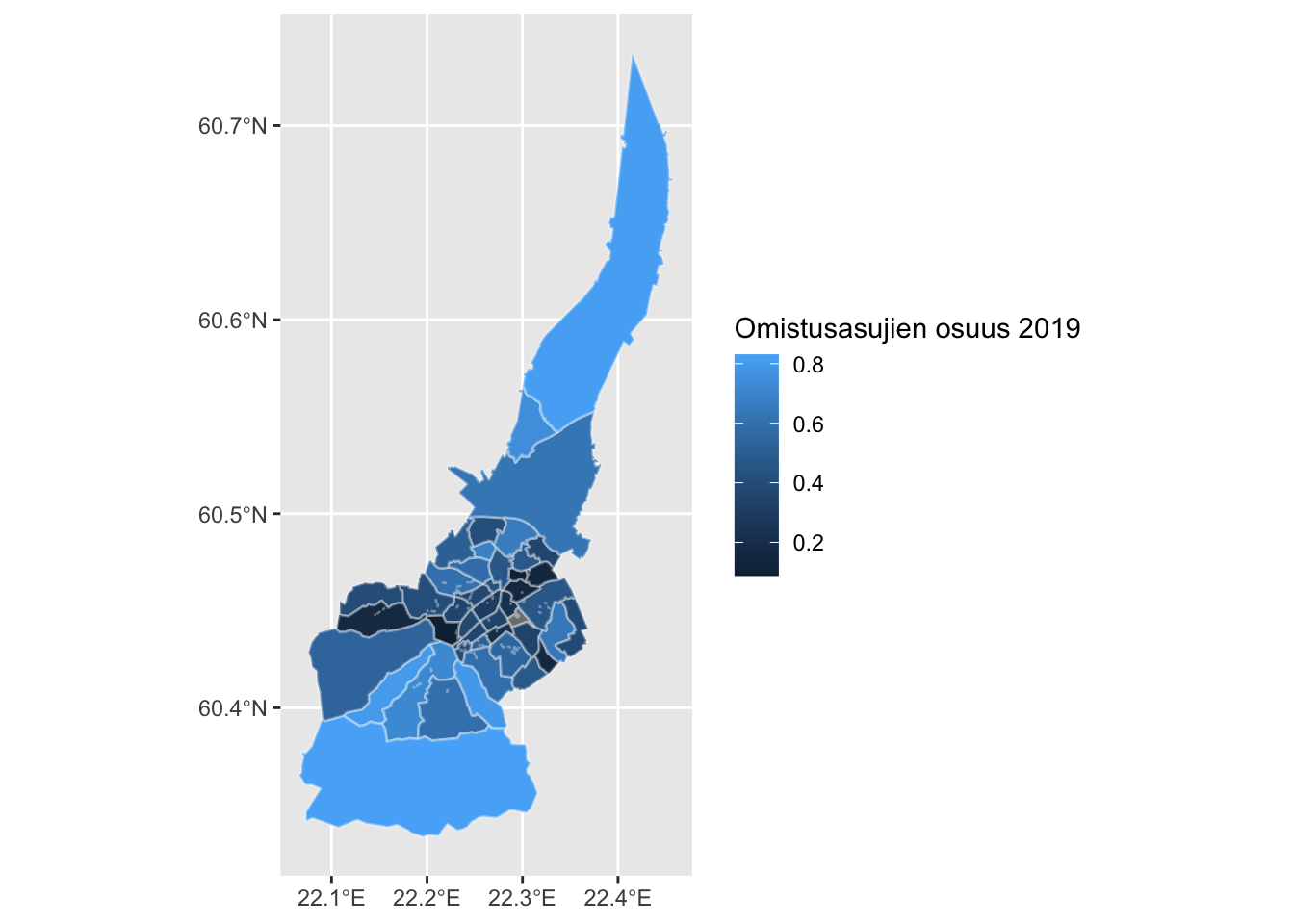
Hyvännäköinen karttakuva saattaa vaatia informatiivisuuden vuoksi lisää tietoja, esimerkiksi alueiden nimet sisältävät labelit. Px-data ei sisältänyt kuin pienalueiden nimet, joten tilastoalueiden ja suuralueiden nimet joutuisi kirjoittamaan joko käsin tai lataamaan toisesta lähteestä.
Tätä blogikirjoitusta varten tein Turun kaupungin aluejaot sisältävän pdf-kartan pohjalta csv-tiedoston, joka sisältää alueiden numerokoodit ja nimet. Aiemmasta jaottelusta poiketen numerokoodit ovat hieman pidempiä, joten muokkaamme dat-objektin koodit csv-tiedostoa vastaaviksi:
dat$pienalue <- paste(dat$suuralue, dat$tilastoalue, dat$pienalue, sep="")
dat$tilastoalue <- paste(dat$suuralue, dat$tilastoalue, sep="")
dat_tilastoalue <- sf::st_make_valid(dat) %>%
dplyr::group_by(tilastoalue) %>%
dplyr::summarise(hallintaperusteet_yhteensa = sum(hallintaperusteet_yhteensa, na.rm = TRUE), omistusasunto = sum(omistusasunto, na.rm = TRUE), muu_asumismuoto = sum(muu_asumismuoto, na.rm = TRUE)) # Luetaan sisään csv-tiedosto, jossa ei ole otsakeriviä
aluekoodit <- read.csv("turku_alueet.csv", header = FALSE)
head(aluekoodit)## V1
## 1 1 Suuralue 1: Keskusta
## 2 101 VI ja VII
## 3 101001 Rauhankatu VII
## 4 101002 Ursininkatu pohj.
## 5 101003 Ursininkatu et.
## 6 101004 Kristiinankatu et.Kuten huomataan, alueiden nimet ja numerokoodit pitkässä muodossa ovat yhdessä sarakkeessa. Ainakin dplyr vaatii, että kaksi yhdistettävää taulukkoa sisältävät ainakin yhden sarakkeen, joka sisältää toisiaan täydellisesti vastaavaa tietoa ja jonka avulla taulukoiden rivit voidaan yhdistää toisiinsa. Fuzzyjoin-pakettia hyödyntämällä tästä täydellisen vastaavuuden vaatimuksesta voitaisiin kenties luopua ja osittainen vastaavuuskin riittäisi, mutta käytän tässä blogikirjoituksessa dplyriä ja muodostan toisiaan täydellisesti vastaavat sarakkeet.
# Poistetaan rivien alusta numero + välilyönti ja muodostetaan uusi sarake
aluekoodit$nimi <- gsub("^[0-9]*[[:blank:]]", "", aluekoodit$V1)
# Muodostetaan uusi muuttuja x1, joka sisältää alun numeroiden + välilyönnin merkkimäärän
x1 <- regexpr("^[0-9]*", aluekoodit$V1)
# Käytetään tietoa merkkimäärästä hyväksi alun numerokoodeja poimittaessa
aluekoodit$numero <- regmatches(aluekoodit$V1, x1)
# Yhdistetään aluekoodit-muuttujan nimet dat-objekteihin numeroiden perusteella
dat_suuralue <- dplyr::left_join(dat_suuralue, aluekoodit, by = c("suuralue" = "numero"))
dat_tilastoalue <- dplyr::left_join(dat_tilastoalue, aluekoodit, by = c("tilastoalue" = "numero"))Visualisoinnit labeleiden kanssa:
ggplot(dat_suuralue) +
geom_sf(aes(fill = omistusasunto / hallintaperusteet_yhteensa), color = alpha("white", 1/3)) +
geom_sf_text(aes(label = nimi), size = 2, color = "red", fontface = "bold", check_overlap = TRUE) +
labs(fill="Omistusasujien osuus 2019")## Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
## give correct results for longitude/latitude data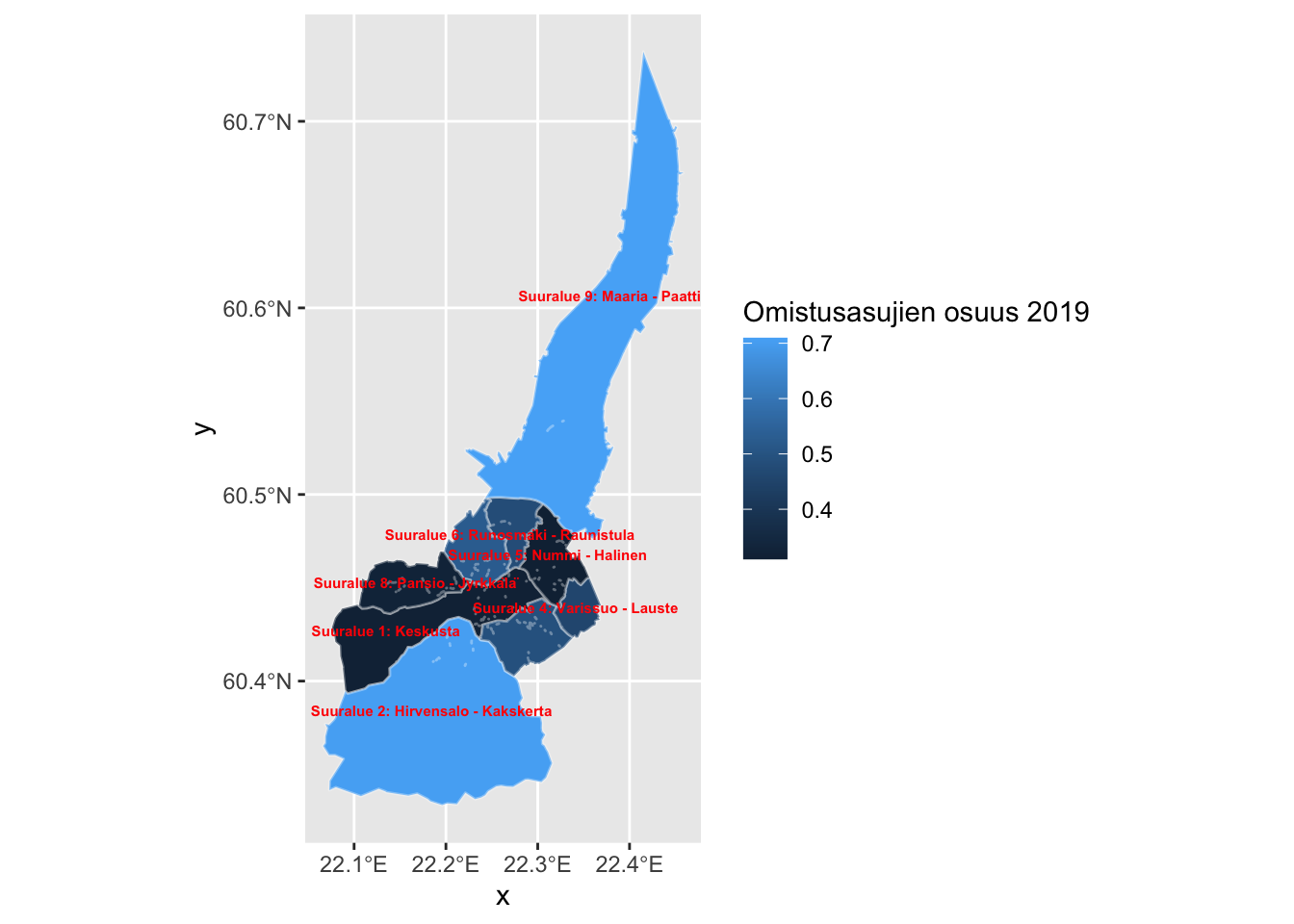
ggplot(dat_tilastoalue) +
geom_sf(aes(fill = omistusasunto / hallintaperusteet_yhteensa), color = alpha("white", 1/3)) +
geom_sf_label(aes(label = nimi), size = 2) +
labs(fill="Omistusasujien osuus 2019")## Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
## give correct results for longitude/latitude data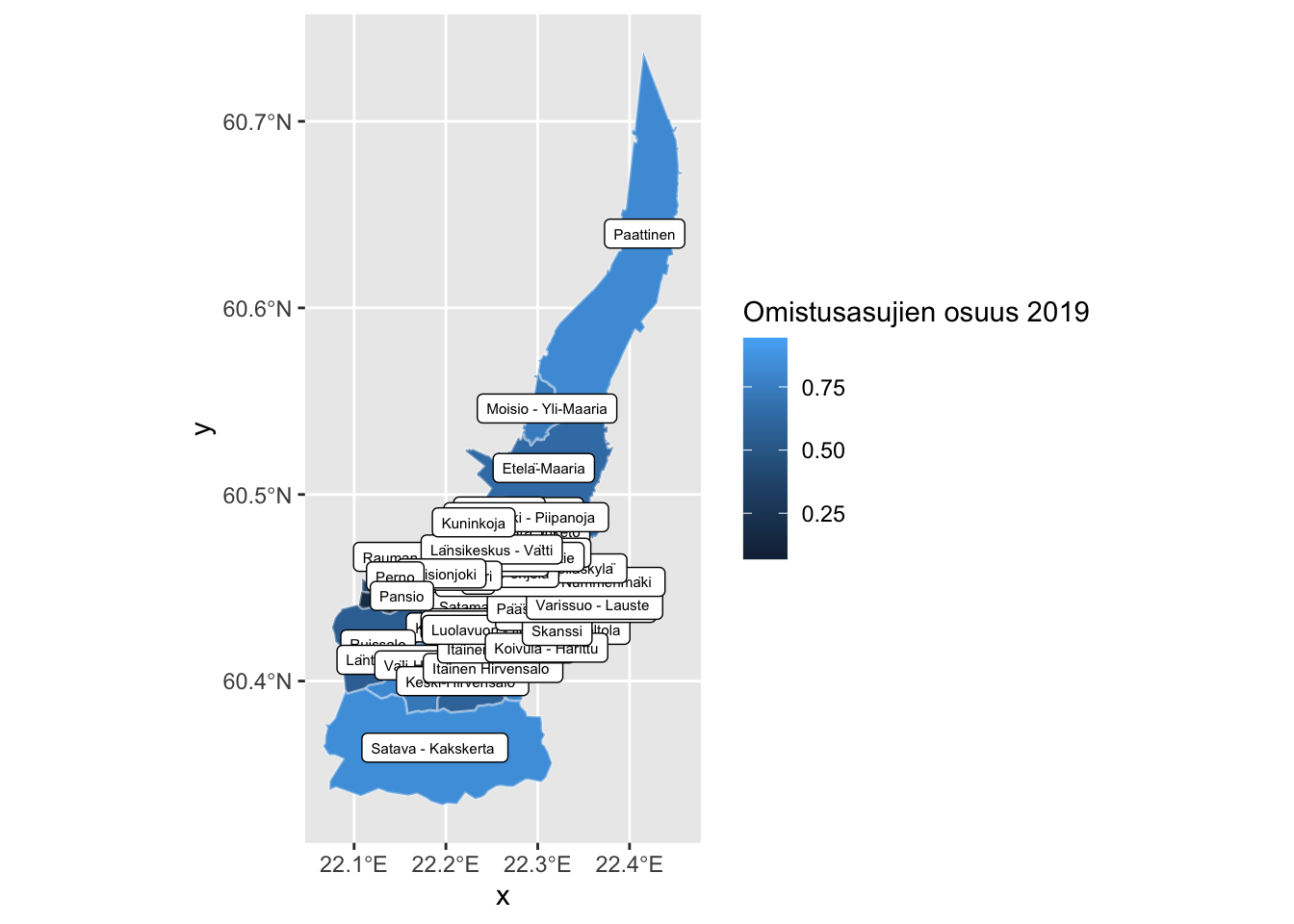
Kuten huomataan, suuri määrä tekstiä tai labeleita saa kartan näyttämään sotkuiselta. Teemakartat ovatkin kaikista hyödyllisimmillään alueellisten trendien, esimerkiksi työttömyysasteen tai asukkaiden keski-iän nopeaan silmäilyyn, jolloin alueen nimikkeellä ei välttämättä ole niin suurta merkitystä.
Toisaalta nimikkeiden kiinnittäminen paikkatietoon ei myöskään ole turhaa, jos paikkatietoja haluaa visualisoida staattisten karttojen sijaan interaktiivisessa näkymässä. Tällöin informaatiota voidaan esittää pop-up -ikkunassa ja labeleiden tekstiä voidaan samalla muotoilla monipuolisesti html-tageja käyttäen.
Esimerkki ajallisen muutoksen visualisoimisesta
Turussa on opiskelijakaupunkina suuri kysyntä opiskelijoille soveltuvista yksiöistä. Seuraavassa esimerkissä katsomme, kuinka yksiöiden määrä on muuttunut vuodesta 2015 vuoteen 2019 eri alueilla.
turku_data_yksiot <- turku_data %>%
filter(Hallintaperuste %in% c("Hallintaperusteet yhteensä"), Huoneistotyyppi %in% c("1h+kk/kt", "1h+k")) %>%
tidyr::pivot_wider(id_cols = c("Osa.alue", "Vuosi"), names_from = "Huoneistotyyppi", values_from = "value") %>%
# Yhdistetään 1h + kk ja 1h+k yhdeksi faktoriksi
mutate(yksiot = `1h+kk/kt` + `1h+k`) %>%
select(-c(`1h+kk/kt`, `1h+k`)) %>%
# Järjestetään data nimen perusteella (ja samalla vuoden perusteella aikajärjestykseen)
group_by(Osa.alue) %>%
arrange(Osa.alue, by_group = TRUE) %>%
# Vertaillaan vuoden 2015 ja 2019 tilannetta, joten lag = 4
mutate(muutos_2015_2019 = yksiot / dplyr::lag(yksiot, n = 4)) %>%
# Jätetään taulukkoon vain 2019 havainnot
filter(Vuosi %in% c("2019"))
# Aineiston tunnusluvut
summary(turku_data_yksiot$muutos_2015_2019)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.2143 1.0000 1.0195 Inf 1.1643 Inf 13# Tarkastellaan, miltä muutoksen suuruus näyttää yläpäässä
turku_data_yksiot %>% arrange(desc(muutos_2015_2019))## # A tibble: 131 x 4
## # Groups: Osa.alue [131]
## Osa.alue Vuosi yksiot muutos_2015_2019
## <fct> <fct> <dbl> <dbl>
## 1 853216047 Toijainen 2019 2 Inf
## 2 853323072 Skanssi 2019 174 58
## 3 853527087 Kuuvuori 2019 508 3.30
## 4 853633099 Impivaara 2019 45 3
## 5 853113037 Otkantti 2019 29 2.9
## 6 853105018 Kakola 2019 523 2.04
## 7 853214041 Jänessaari 2019 2 2
## 8 853526081 Asuin-Itäharju 2019 395 1.98
## 9 853708027 Autistenaukio - Oikotie 2019 129 1.87
## 10 853736110 Ruohonpää länt. 2019 255 1.67
## # … with 121 more rows# Yhdistetään aineisto geospatiaaliseen dataan
dat2 <- dplyr::inner_join(turku_pienalueet, turku_data_yksiot, by = c("id" = "Osa.alue"))Huomataan, että Skanssin kaupunginosassa yksiöiden rakentamistahti on ollut huomattavasti nopeampaa kuin muualla Turussa (2016 3 yksiötä, 2019 174 yksiötä). Tämä selittyy Skanssin kaupunginosan edelleen jatkuvalla kehityksellä. Toisella alueella, Toijaisessa, muutoksen suuruus on “mittaamattoman suuri” alussa olleen yksiöiden lukumäärän oltua 0. Teemakartan piirtämisen kannalta näin räikeästi muista poikkeavat outlierit tekee pääasiassa muutaman prosentin vuosittaisten muutosten visualisoimisesta mahdotonta, joten poistamme kaksi suurinta havaintoa ja piirrämme lopuksi kartan:
dat2 <- dat2 %>%
mutate(muutos_2015_2019 = ifelse(muutos_2015_2019 > 3, NA, muutos_2015_2019))
ggplot(dat2) +
geom_sf(aes(fill=muutos_2015_2019), color = alpha("white", 1/3)) +
labs(fill="Yksiöiden määrän muutos 2015-2019, 100 %") +
scale_fill_gradient2(low = "red", midpoint = 1.0, mid = "white", high = "blue", space="Lab")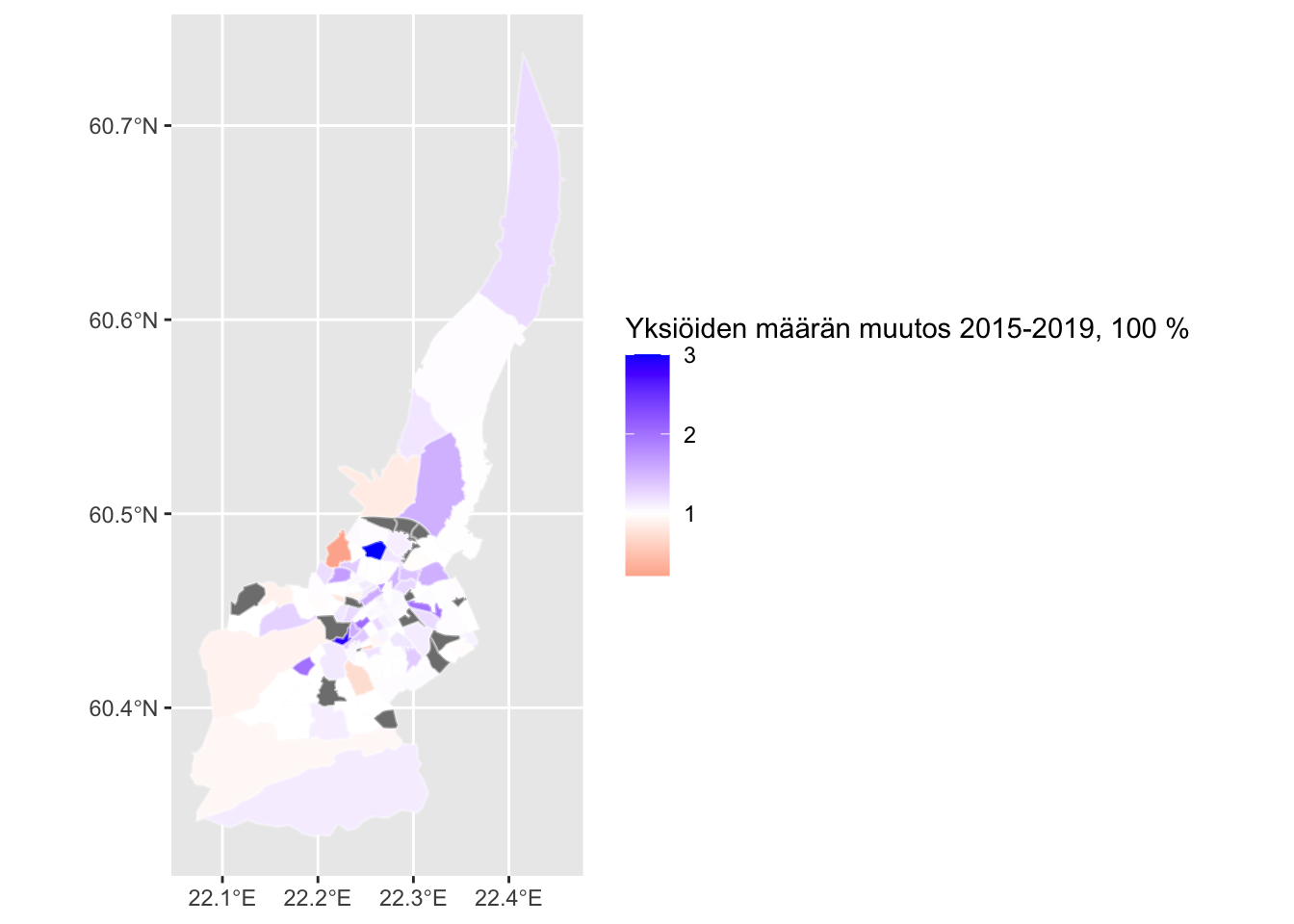
Suuri osa kartasta maalautuu valkoiseksi, mikä tarkoittaa että neljän vuoden aikana yksiöiden määrän kasvu ei ole ollut järin suurta. Toisaalta on hyvä muistaa, että tämän kaltainen yksinkertainen tarkastelu ylikorostaa pienillä alueilla tapahtuvia muutoksia ja tekee jo ennestään väkirikkailla alueilla tapahtuvat absoluuttiset muutokset näkymättömiksi.
Vertailun vuoksi vielä kaikkien asuntojen absoluuttisia määriä kuvaava teemakartta:
turku_data_asunnot <- turku_data %>%
filter(Hallintaperuste %in% c("Hallintaperusteet yhteensä"), Huoneistotyyppi %in% c("Huoneistotyypit yhteensä")) %>%
tidyr::pivot_wider(id_cols = c("Osa.alue", "Vuosi"), names_from = "Huoneistotyyppi", values_from = "value") %>%
rename(kaikki_asunnot = `Huoneistotyypit yhteensä`) %>%
group_by(Osa.alue) %>%
arrange(Osa.alue, by_group = TRUE) %>%
mutate(muutos_2015_2019 = lag(kaikki_asunnot, n = 0) - lag(kaikki_asunnot, n = 4)) %>%
filter(Vuosi %in% c("2019"))
summary(turku_data_asunnot$muutos_2015_2019)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## -65.00 3.00 14.00 137.38 75.25 8308.00 11dat3 <- dplyr::inner_join(turku_pienalueet, turku_data_asunnot, by = c("id" = "Osa.alue"))
ggplot(dat3) +
geom_sf(aes(fill=muutos_2015_2019), color = alpha("white", 1/3)) +
labs(fill="Asuntojen määrän muutos 2015-2019, kpl") +
scale_fill_gradient2(low = "red", high = "blue", space="Lab")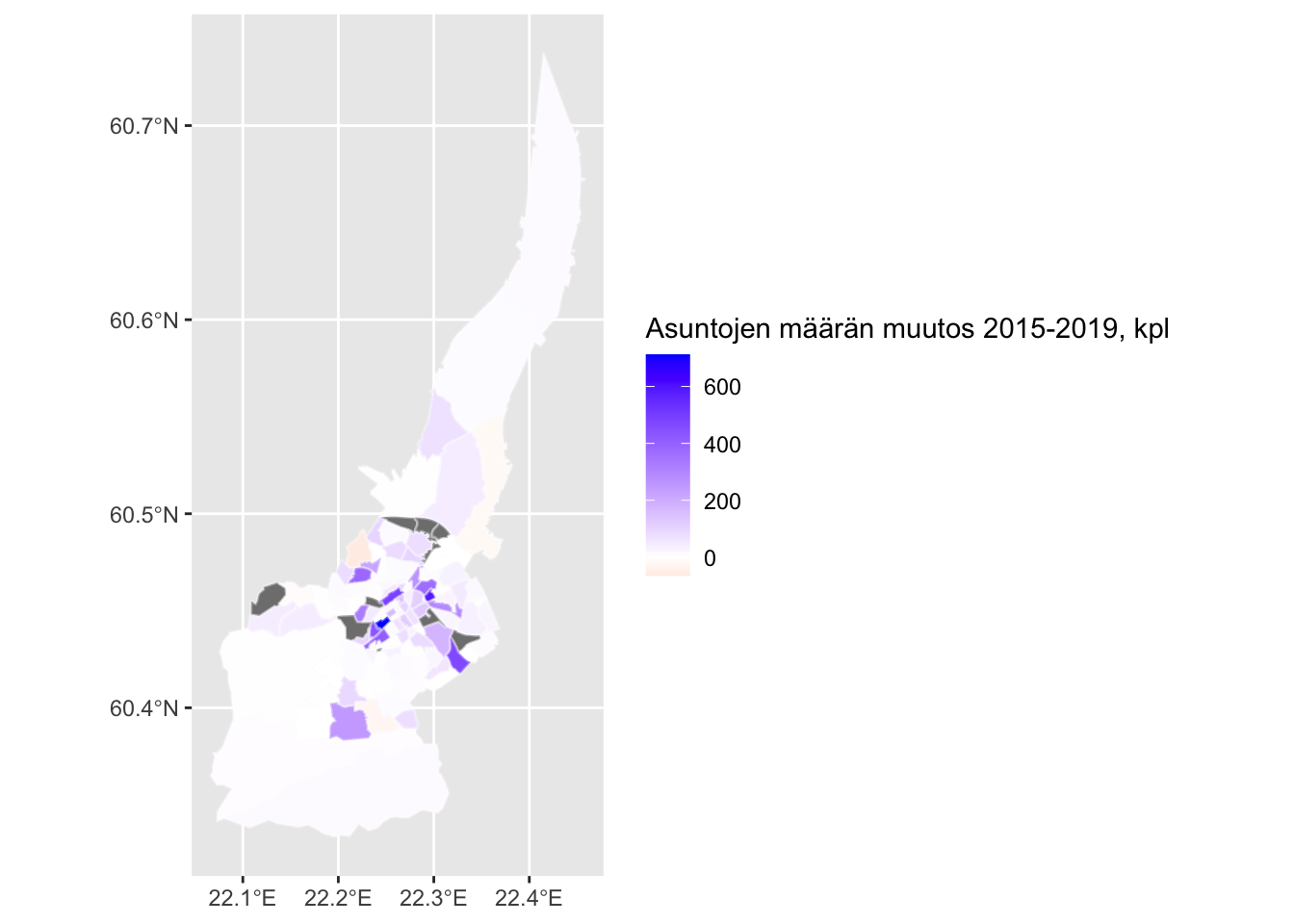
Lopuksi
Tämän kirjoituksen tarkoituksena oli demonstroida, kuinka Turun julkistamaa pienaluedataa voidaan visualisoida yleisesti käytössä olevia R-paketteja hyödyntämällä.
Jatkokehityskohteena joitakin blogissa esiteltyjä työvaiheita olisi epäilemättä hyvä kiteyttää helpommin käytettävämpään ja pysyvämpään muotoon, esimerkiksi erillisen R-paketin muodossa. Koneellisesti luettava valmis lista Turun aluekoodeista on esimerkki tiedosta, josta on hyötyä monissa alueellisen dataan liittyvissä toimenpiteissä ja olisi hyvä olla helposti saatavilla. Toinen kehityskohde voisi olla nykyisellään hieman hankalasti käytettävissä olevan .px-muotoisen datan uudelleenpaketoiminen johonkin helpommin hyödynnettävään formaattiin.
Yksinään Turun aluedata jää hieman ontoksi. Turun alueiden vertailu esimerkiksi muiden 6Aika-hankkeeseen osallistuvien suurempien kaupunkien (Helsinki, Espoo, Vantaa, Turku, Tampere, Oulu) alueisiin voisi olla jo mielekkäämpää.
Aiheen äärelle varmasti palataan vielä.