Johtopäätöksiä tai edes käyttökelpoista visualisaatiota ei useinkaan pysty tekemään datasta suoraan, vaan tarvitaan mallintamista. Mallintaminen erottaa kiinnostavan ja ei-kiinnostavan variaation, ja auttaa johtopäätösten luotettavuuden arvioinnissa.
Pienehköissä projekteissa mallintaminen perustuu valmiisiin mallikohtaisiin ohjelmistopaketteihin. Esim. jos työskennellään R:ssä, regressiomalli syntyy lm()-funktiolla. Jos ennustettavassa on patologisen oloisia poikkeamia, voidaan lm():n sijaan käyttää robustia regressiota. Epälineaaristen vaikutusten huomiointi onnistuu parhaiten mgcv-paketin gam()-funktiolla. Jos selittäjissä on kovin moniarvoisia nominaalimuuttujia ja data on harva ja iso, turvaudutaan lme4-pakettiin, jne. Pakettia valitessa pitää päättää mitkä datan piirteet unohtaa, koska mikään paketti ei ole tarpeeksi joustava.
Rakenteinen data
Nykyään puhutaan rakenteettomasta datasta (unstructured data) ja tarkoitetaan usein datan esitysmuotoa: se ei ole relaatio-tietokantaan sopivina taulukoina. Tilastollisesti puhutaan rakenteellisesta datasta silloin kun ei ole osoitettavissa mittausyksikköä, riippumatonta ”näytettä”. Esim. spatiaalinen tai aikasarjadata on luonnostaan rakenteellista, koska vierekkäiset näytteet ovat yleensä samantyyppisiä. Sama pätee hierarkiaan: jos maitten sisällä on läänejä, läänien sisällä kuntia, ja kuntien sisällä asukkaita, ja näistä on vielä toistomittauksia, ei datasta ole osoitettavissa ”näytteen” tasoa, josta olisi riippumattomia toistoja. Hieman hämäävästi, esitysmuodoltaan ”rakenteeton” data on usein tilastollisesti rakenteellista, koska rakenne on oikeasti niin monimutkainen että sen esittämisestä relaatiokannan keinoin on luovutettu.
Riippuvuuksia sisältävän datan kanssa valmispakettien ongelmat korostuvat. Riippuvuusrakenteet ovat aina datakohtaisia, ja niiden esittämiseen tarvitaan joustava mallinnuskieli.
Tee se itse?
Vaihtoehto valmiiden mallikohtaisten pakettien käytölle on koodata mallin estimointi itse. Tutkimustyössä uuden mallin estimoinnin koodaaminen itse on perusteltua, käytännön mallinnusprojekteissa vain jos mallinnuksen hyöty on huomattava. Etenkin avoimen datan projekteissa budjetti on usein pieni.
Itse koodaamisen ja mallispesifien pakettien välissä on ollut 1990-luvun alusta asti BUGS-perheen työkaluja (WinBUGS, OpenBUGS, JAGS), joilla voi helposti koodata melkein minkä tahansa mallin. Näiden käyttö on rajoittunut pienehköihin datoihin, koska estimointi tulkattavalla Gibbs-sämplerikoodilla on hidasta.
Todennäköisyysohjelmointi
Tilanne on nyt muuttumassa. Stan-ohjelmistopaketti tukee hamiltonilaiseen mekaniikkaan perustuvaa HMC:tä, joka on yleensä Gibbs-sämpleriä merkittävästi nopeampi. Stan tuottaa mallinkuvauksesta C++-koodia, joka käännetään natiivikirjastoksi. Matriisioperaatioihin Stan käyttää tehokasta Eigen-kirjastoa. HMC tarvitsee likelihood-funktion ensimmäisen asteen derivaatat: Stan laskee nämä analyyttisesti mallikoodin perusteella. Stan osaa myös laskea perinteisiä MAP/ML-ratkaisuja BFGS-optimoinnilla. Myöhemmin Staniin on tulossa analyyttinen toisen asteen derivointi (RHMC, Laplace-approksimaatiot) ja luultavasti myös approksimatiivisia estimointimenetelmiä kuten EP (expectation propagation) ja variationaaliset posteriori-approksimaatiot.
Stan onkin selvä kehitysaskel kohti uutta ohjelmistoteknistä suuntausta, todennäköisyysohjelmointia (probabilistic programming). Idea on kuvata vain dataa tuottava mekanismi, generatiivinen malli, ja mahdollisesti käytettävien approksimaatioiden taso ja muoto. Kääntäjä huolehtii estimointifunktionaalisuuden tuottamisesta. Näin pystytään käyttämään entistä merkittävästi joustavampia malleja.
Stanin ohjelmointi vaatii tietenkin kokemusta generatiivisista malleista, ja myös on ymmärrettävä käytettävän estimointiprosessin ominaisuudet, jotta monimutkaisemmasta mallista saa tehokkaan. Esimerkiksi parametriavaruuden tai oikeammin posteriorin geometrian olisi syytä olla sämplerille helppo, ilman ”todennäköisyyskuiluja”. Joskus myöhemmin RHMC tai parempi kääntäjä voi helpottaa tilannetta geometrian osalta, mutta toisaalta isomman datan kanssa on aina tehtävä oikaisuja, ja niiden valinta vaatii ammattitaitoa. Tulevaisuuden kääntäjät voivat ymmärtää ja optimoida parametriavaruuden geometriaa.
Stanin ja vastaavien todennäköisyysohjelmoinnin kielien päälle kehittyykin luultaavasti sovelluskohtaisi erityisratkaisuja. Tästä on jo esimerkkikin: glmer2stan sallii lme4:n mallinkuvauksien (formula) käytön Stanin kanssa.
Muista todennäköisyysohjelmoinnin projekteja ovat mm. PyMC, JAGS, Infer.NET ja Venture. DARPA rahoittaa todennäköisyysohjelmoinnin tutkimusta PPAML-ohjelmassaan.
Kilpisjärven kesät
(Alla olevan intron koodit ovat Githubissa.)
European Climate Assessment -sivuilta on ladattavissa lämpötilamittausten aikasarjoja yksittäisiltä mittausasemilta. Sieltä voi ladata myös Kilpisjärven lämpötilasarjan päivätasolla. Jos haluamme tietää näkyykö kesien lämpeneminen jo Kilpisjärven tiedoissa, päiväkohtaiset havainnot kannattaa ensin aggregoida vuosittaisiksi kesäkuukausien keskilämpötiloiksi: (Oma aikasarjani on peräisin suoraan Ilmatieteen laitokselta, minkä ei pitäisi muuttaa tuloksia, ainakaan oleellisesti.)
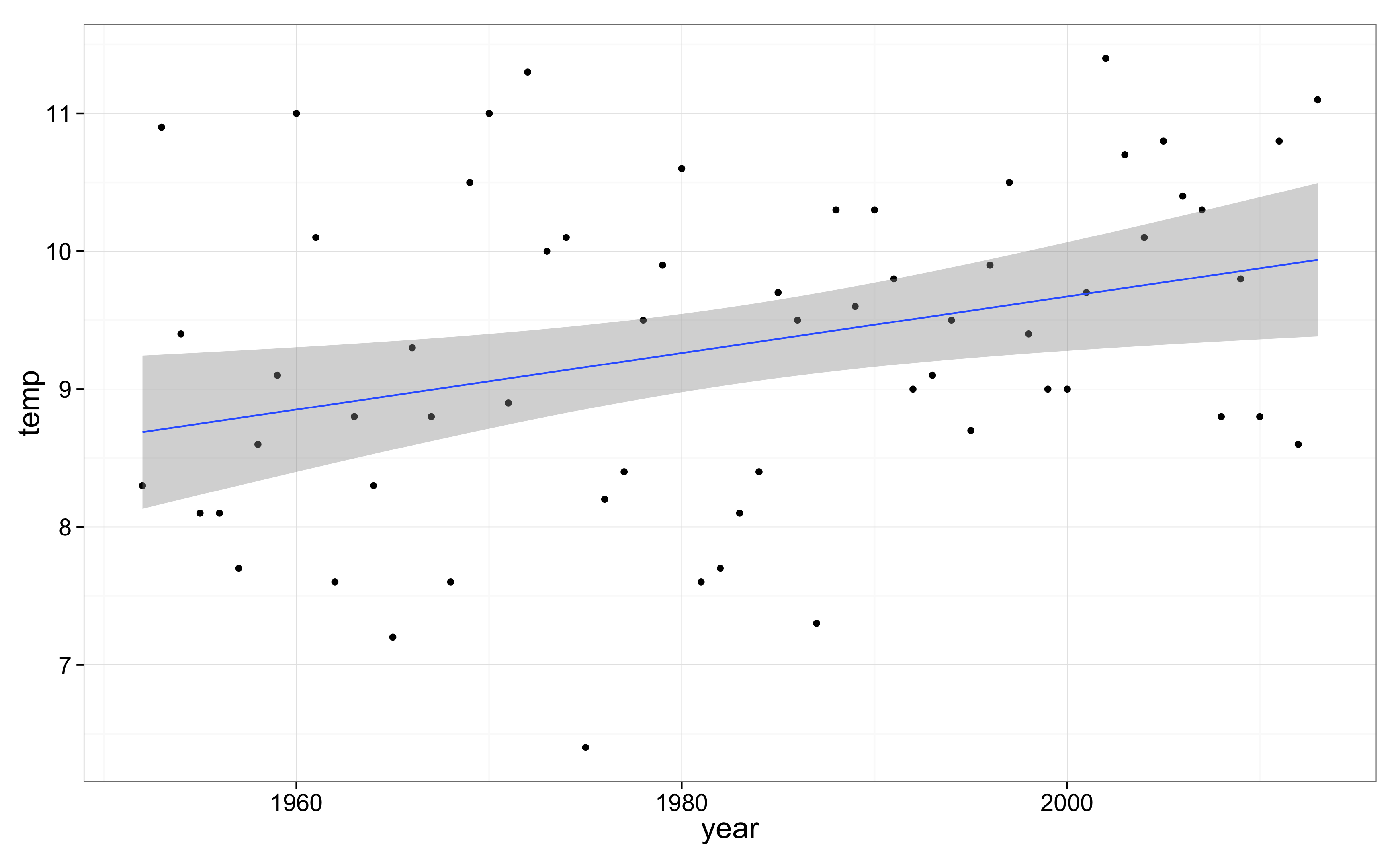
Sarjaan on helppo sovittaa trendi R:ssä:
m <- lm(temp ~ year, data=d)
summary(m)
10*(c(-1.96, 1.96)*sqrt(diag(vcov(m))["year"])+coef(m)["year"])
Trendi poikkeaa nollasta merkitsevyystasolla p=0.0115, ja trendin 95% luottamusväli on 0.05–0.36 astetta per vuosikymmen. Eli kyllä Kilpisjärven kesät näyttäisivät jo lämmenneen!
Mieltä jää kalvamaan kuitenkin epäilys autokorrelaatiosta. Kylmät ja lämpimät vuodet tunnetusti esiintyvät ainakin globaaleissa aikasarjoissa peräkkäin, johtuen mm. suursäätilan keskimääräisestä pysyvyydestä jopa vuosien yli (AO/NAO), merten tilasta (ENSO), tulivuorista ja hieman auringon aktiivisuudestakin. Jos näin, peräkkäiset vuodet eivät ole riippumattomia, näytteiden efektiivinen määrä on pienempi kuin vuosien (62), ja p-arvo ja luottamusväli ovat ylioptimistisia. Myöskin sarjan alkupuolella on isoja poikkeamia keskimääräisestä. Ehkä ne rikkovat normaalijakaumaoletukset ja vaikuttavat p-arvoon?
Eli näinkin yksinkertaisella datalla saadaan aikaan hankala tilanne, jossa ratkaisuksi pitää lähteä etsimään R:stä aikasarjapakettia, joka sallisi trendien estimoinnin ja mielellään robustin regression. Sellainen voi ollakin olemassa, mutta ei ole ihan helppo löytää.
Lineaarinen regressio Stanilla
Kokeilemme siis mallintamista Stanilla. Aluksi lineaarinen regressio, eli sama malli jonka sovitimme yllä lm()-funktiolla. Mallin kuvaus on alla. Huomaa että malliin ei ole yksinkertaisuuden vuoksi määritelty prioreita. Yleensä ne kannattaa määritellä.
data {
int<lower=1> N; real y[N]; }
parameters {
real baseline; real trend; real<lower=0> sigma; }
model {
for (t in 1:N) y[t] ~ normal(baseline + trend*t, sigma); }
… ja R-koodi:
library(rstan)
sdat <- list(N = nrow(d), y = d$temp)
m.slm <- stan_model("kj-lm.stan")
fit <- sampling(m.slm, data=sdat, iter=20000)
trends <- extract(fit, "trend")[[1]]
2*sum(trends<0)/length(trends)
quantile(trends, c(0.025, 1-0.025))
Vähempikin määrä iteraatioita riittäisi, esim. 1000 näytettä per ketju antaa yhteensä 500–800 efektiivistä näytettä posteriorista ja vie aikaa n. 0.7 sekuntia. Mutta nyt haluamme tarkan p-arvon vertailua varten. p-arvo on 0.0125, eli melko lailla sama kuin R:n lm()-funktiolla saatu.
Robusti regressio
Mallin residuaali on helppo vaihtaa t-jakaumaksi:
data {
int<lower=1> N; real y[N]; }
parameters {
real baseline; real trend; real<lower=0> sigma; real<lower=0> df; }
model {
df ~ normal(0, 20);
for (t in 1:N) y[t] ~ student_t(df+1, baseline + trend*t, sigma); }
p-arvo (0.0092) ja trendin luottamusväli (0.05–0.37) eivät juurikaan muuttuneet, mutta hieman sarjan isot alkupään poikkeamat ovat häirinneet trendin estimointia. Tähän viittaa myös virhejakauman vapausasteiden posteriori: vapausasteilla 1–10 jakaumasta tulee jo selvästi normaalijakaumaa pitkähäntäisempi.
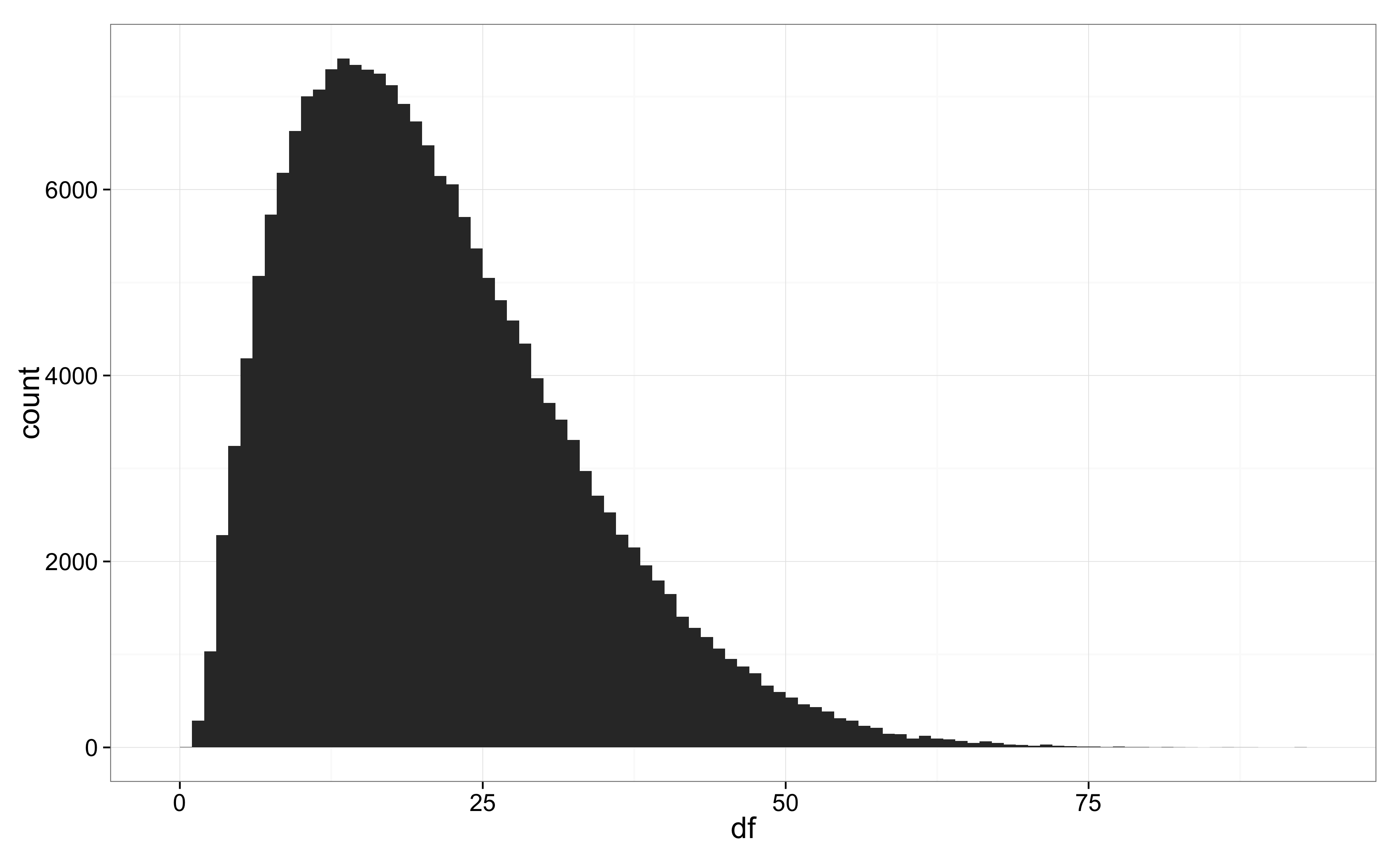
Autokorrelaatiot
Unohdamme hetkeksi residuaalit, ja siirrymme autokorrelaatioiden ongelmaan. Lämpötilasarjassa voisi olla pitkän aikavälin syklisyyttä, mutta datassa ei silmämääräisesti näy kummempia kuoppia, ja sellaisten erottaminen trendistä on jo määritelmällisesti vaikeaa. Keskitymme siis lyhyen aikavälin (1–10 vuotta) korrelaatioihin.
Yksi vaihtoehto olisi parametrisoida residuaaleille korrelaatiomatriisi. Helpompaa ja laskennallisesti tehokkaampaa on kuitenkin tehdä peräkkäisistä estimointivirheistä lineaarisesti riippuvia. Eli määrittelemme kertoimet theta[lag], lag=1…10, joilla aiempi estimointivirhe kerrotaan ja otetaan huomioon kunkin vuoden kohdalla. Näiden päälle tuleva ’uusi’ estimointivirhe on sitten normaalijakautunutta riippumattomasti joka vuodelle. Mallia kutsutaan aikasarja-analyysissä MA-malliksi.
Stan-koodissa joka vuodelle lasketaan virhe, ensin ottaen koko estimointivirhe (havainto miinus trendi) ja vähentäen tästä vanhat, ikäänkuin muistetut virheet:
data {
int<lower=1> N; real y[N];
int<lower=1> D; // Maximum lag. }
parameters {
real baseline; real trend;
real<lower=0> sigma;
vector<lower=-1, upper=1>[D] theta; }
transformed parameters {
vector[N] eta;
{ vector[N] err;
for (t in 1:N) {
eta[t] <- trend*t + baseline;
for (lag in 1:D) {
if (t>lag) eta[t] <- eta[t] + theta[lag] * err[t-lag]; }
err[t] <- y[t] - eta[t]; }}}
model { y ~ normal(eta, sigma); }
Koko mallikoodi on tiedostossa kj-correlated.stan, ja muistutuksena, käytetyt R-komennot yleisemminkin tiedostossa kj.R.
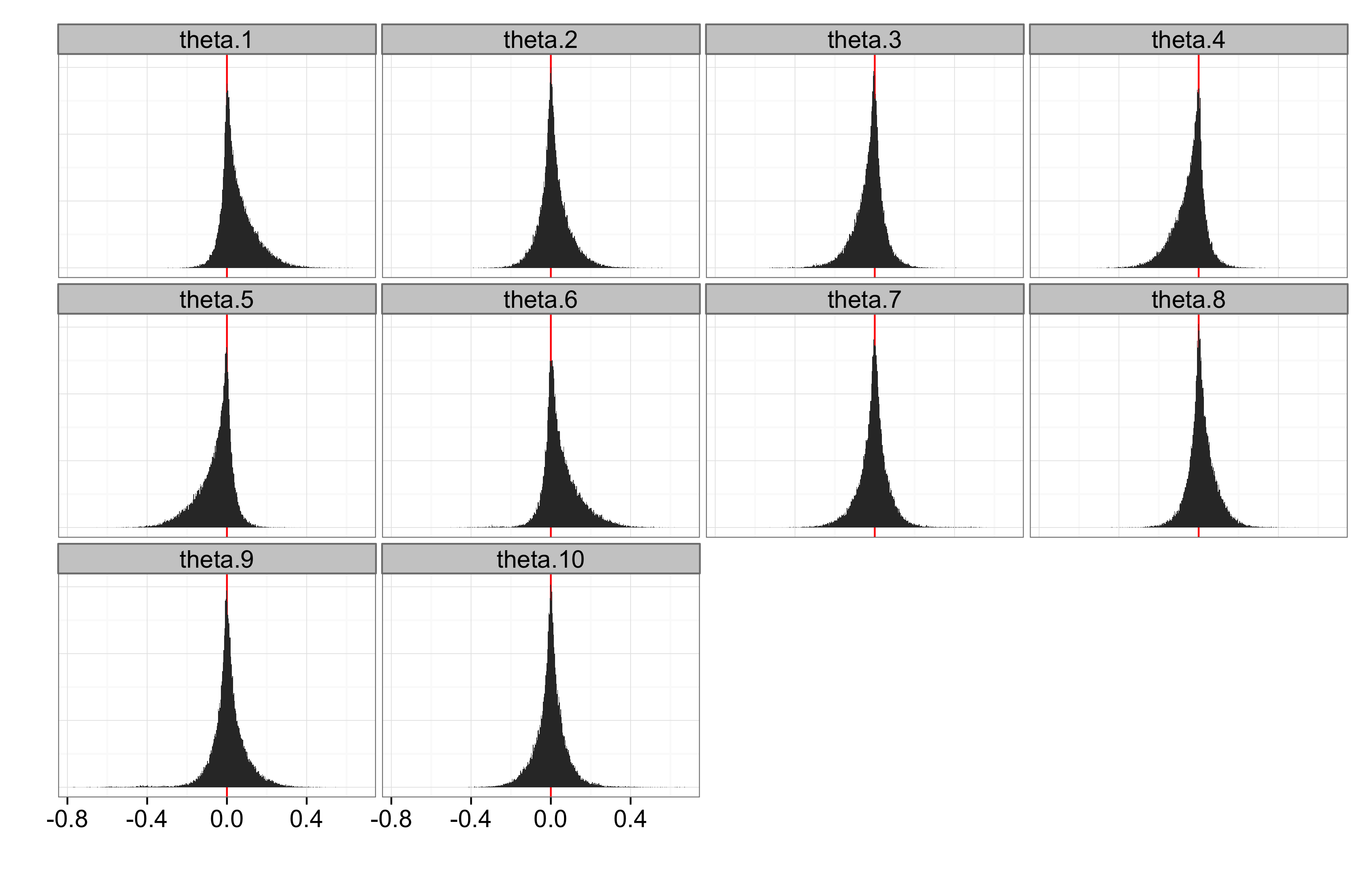
Nyt vastassa on ongelmia: 3000 MCMC-iteraatiota ei näytä riittävän virheiden (err) ja theta-parametrien kunnolliseen estimointiin. Sovitettu malliobjekti fit kertoo samaa: kovin montaa riippumatonta näytettä ei ole saatu, ja neljästä eri ketjusta saadut theta-estimaatit poikkeavat liikaa toisistaan. Alla ruutukaappaus kommennon plot(fit, pars=”theta”) jäljiltä. Viivat ovat 80% luottamusvälejä ja pisteet yksittäisten ketjujen mediaaneja:
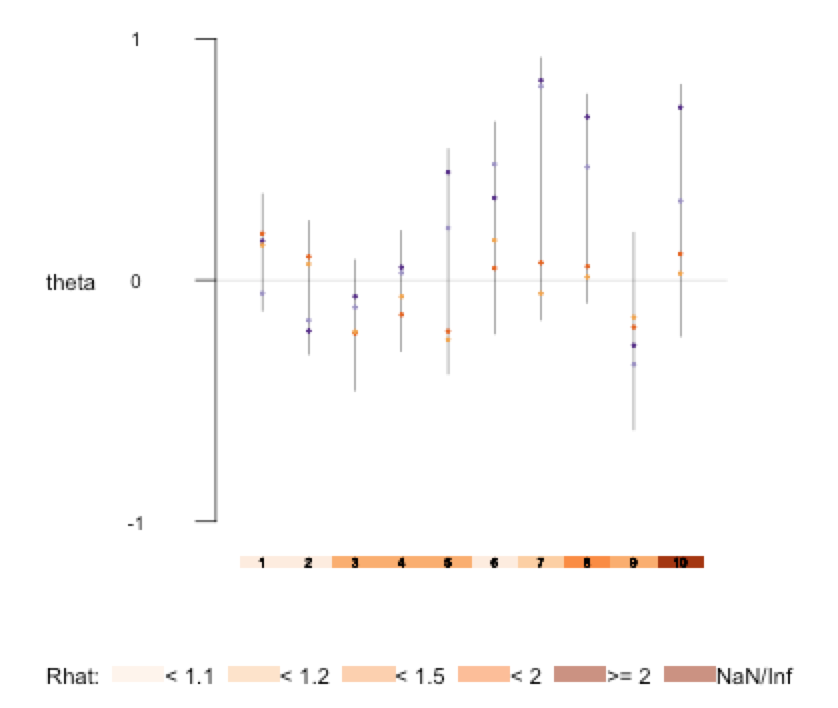
Aikasarjakerrointen paimennusyrityksiä
Ongelmana on ehkä trendin ja autokorrelaation keskinäinen epäidentifioituvuus. Myöskin loppupään theta-kertoimet ovat suuruusluokaltaan ja keskinäisiltä eroiltaan epärealistisia, eli priori theta-kertoimille on liian löysä.
Malliin on helppo lisätäoletus theta-kerrointen mahdollisesta pienuudesta ja samankaltaisuudesta:
theta ~ normal(0, theta_sd); theta_sd ~ normal(0, .5);
Ko. priori sallii myös isot ja keskenään erisuuruiset kertoimet, jos data antaa niille tukea. Koko mallikoodi on tiedostossa kj-correlated-pooled-theta.stan. Huomaa että parametrin määrittelystä on poistettu rajoitus välille -1…1, koska se ei ole yhteensopiva normaalijakautuneen priorin kanssa. Sensijaan itse malliin on lisätty parametrille tanh()-muunnos, joka pitää ottaa huomioon mallia tulkittaessa.
Näiden muutosten jälkeen useimmat ketjut satunnaisalustuksilla konvergoituvat samanlaiseen lopputulokseen. Kun uskomme tämän olevan mallin oikea posteriori, voimme ajaa pitemmän ajon p-arvoa varten. Autokorrelaatiot, jos niitä on, tekevät tuloksista hieman epävarmempia koska efektiivinen näytteiden määrä pienenee. Tällä kertaa p-arvo on 0.016 ja 95% luottamusväli 10 vuoden trendille 0.04–0.37. Merkittävää muutosta ei siis autokorrelaatioista tai 11 parametrin lisäämisestä syntynyt. (Parametrien optimointi maximum likelihood -mielessä vastaisi alkuperäistä MA-mallia ilman theta-kerrointen prioria, eikä siis toimisi kovin hyvin.)
Kaikki yhdessä
Lisäämme malliin vielä lopuksi alkuperäisen mallin t-jakautuneet residuaalit. Pääpiirteiseen ajoon (3000 näytettä, 100–1000 efektiivistä näytettä) kuluu aikaa n. 3 sekuntia, ja pitkään ajoon (11000 efektiivistä näytettä trendille) tarkkaa p-arvoa varten 88 sekuntia. ”Lopullinen” p-arvo 0.013 on lähes identtinen alkuperäisen lm()-funktiolla saadun p-arvon kanssa (0.0115). Oliko vaivannäkö Stanin kanssa turhaa? Ei aivan, sillä voimme olla rauhallisin mielin autokorrelaation ja sarjan alkupään suurten poikkeamien osalta. Ne ovat nyt mallissa mukana.
P-arvon tuijottamisen jälkeen on hyvä pitää mielessä (vuosi)trendin posteriorijakauma:
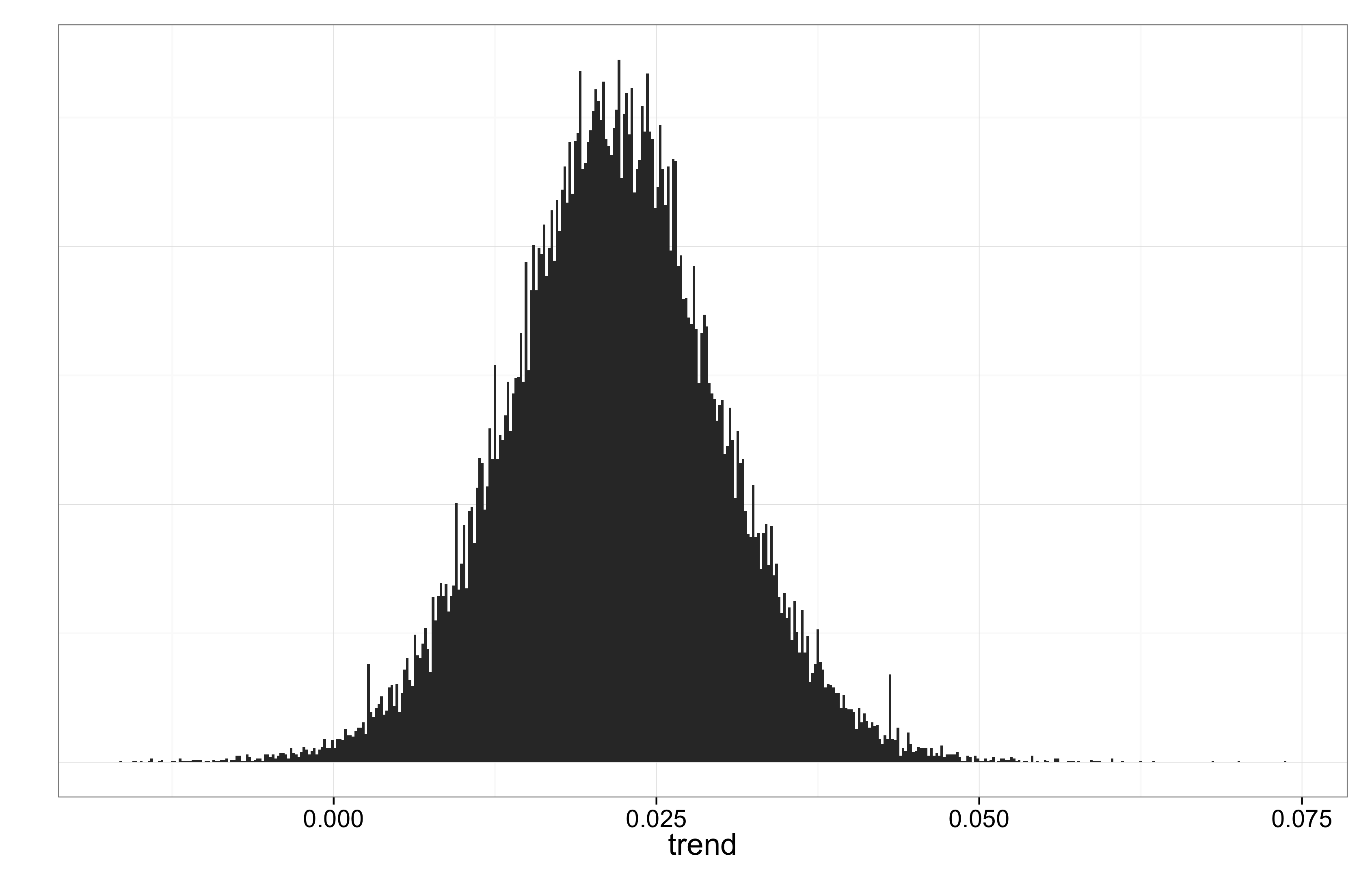
P-arvolla on teoreettista mielenkiintoa malleja vertailtaessa ja pyhitettyjen rajojen (0.01, 0.05) alittaminen on tietenkin vakuuttavaa. Mutta johtopäätösten kannalta oleellista on, että trendi on luultavasti ollut luokkaa 0.1°–0.3° per vuosikymmen.
Autokorrelaatioiden olemassaolo jää epäselväksi, mutta päätöstä niiden suhteen ei tarvitse tehdäkään: malli integroi eri mahdollisuuksien yli. theta-kerrointen posteriorit eivät poikkea merkitsevästi nollasta. Toisaalta esim. ensimmäinen kerroin on luultavasti positiivinen:
Sovittuiko data
Lopuksi vielä vilkaisemme mallin residuaaleita (residuaaliposteriorin keskiarvo, vrt. koodi tiedostossa kj.R):
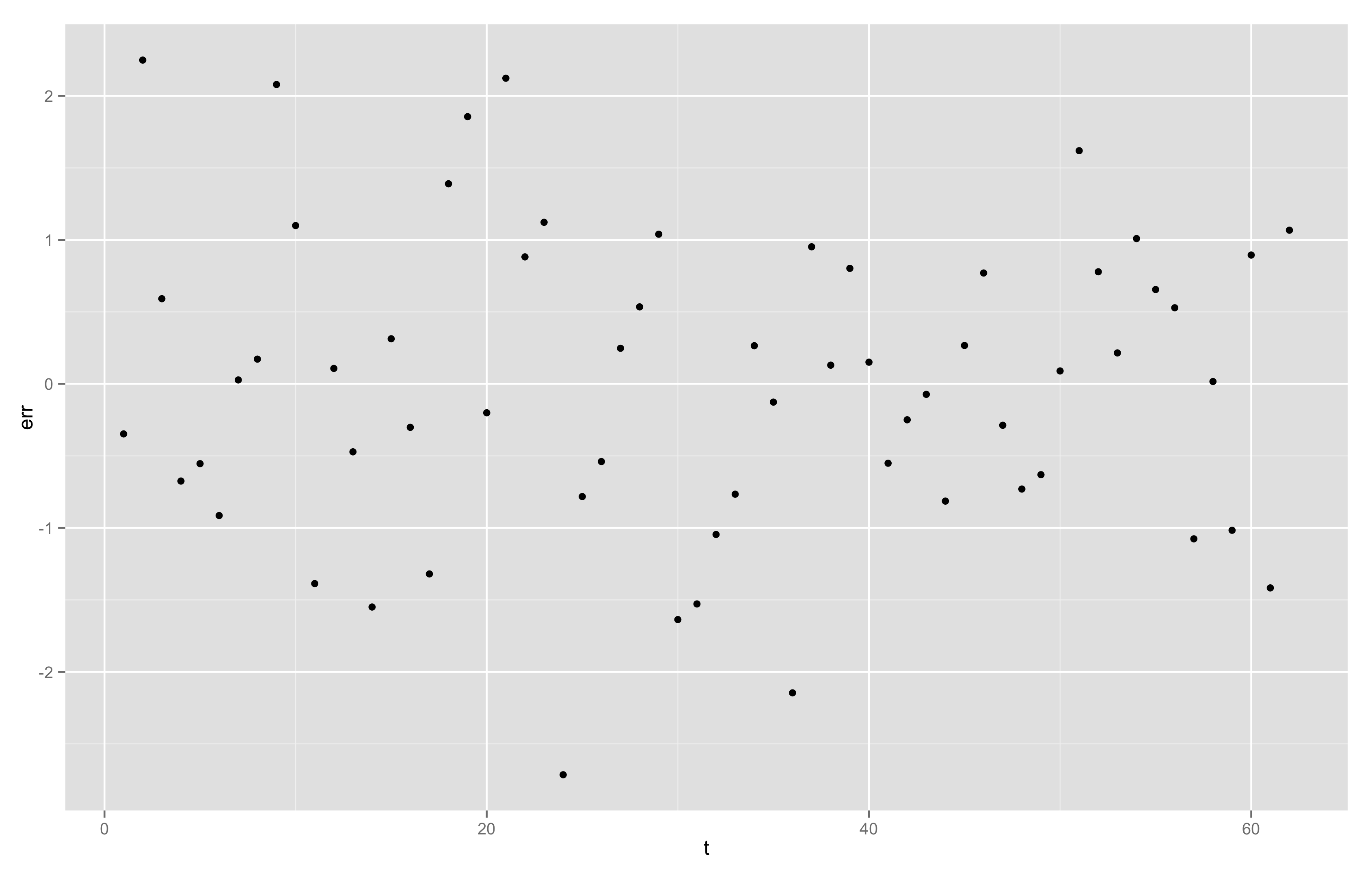
Residuaaleissa ei näy merkillisyyksiä, joskin keskivaiheilla aikasarjaa näkyy aavistus notkahduksesta. Tiedostossa kj2.stan on vielä rikkaampi malli, jossa on ajan suhteen myös toisen asteen termi. Sen kerroin on positiivinen 80% todennäköisyyllä.
Mallin ydinkoodi on hyvä, parempi kuin Stanin manuaalin versiossa 2.1.0 oleva MA-mallin koodi. Mutta malliin voisi lisätä (epäinformatiiviset) priorit regressiokertoimille ja residuaaleille. Tällä kertaa prioreilla ei liene käytännön merkitystä, mutta joskus niiden puuttuminen voi johtaa estimointiongelmiin. Myöskään satunnaisinitialisaatio (init=”random”) ei toimi kaikille ketjuille. Ketjut voi alustaa myös deterministisesti (init=0), ja niin on pitemmille ketjuille tehtykin. Ne ovat silloin vähemmän satunnaisia ainakin alkupäästään, joten ketjuja ei voi luotettavasti verrata toisiinsa konvergenssin varmistamiseksi. Muitakin vaihtoehtoja on, esim. MAP-estimaatin voi etsiä optimizing()-komennolla ja käyttää sitä hieman perturboituna initialisointiin. MAP ei kuitenkaan hierarkian ylempien tasojen osalta toimi, koska optimoinnin kannalta theta-parametrit kannattaa vapauttaa (hyperpriorin puitteissa) täysin.
Mallia voisi laajentaa ottamalla siihen mukaan esim. useita vuodenaikoja, tai useampia mittausasemia. Näiden keskinäisten riippuvuuksien hallintaan voisi käyttää vaikkapa gaussisia prosesseja.
Huomioita
Lineaarinen perusmalli sovittui Stanilla helposti, samoin kuin t-residuaalimalli, mutta autokorrelaatiomallin onnistunut estimointi vaati useiden erilaisten parametrisaatioiden kokeilua, ja lopulta samplerin parametrien konfiguraatiota (stepsize_jitter=0.3, vrt. koodi). Näin lienee yleisemminkin. Stanin manuaalista löytyy valmiiksi koodattuna monta erilaista standardimallia. Mutta kun alkaa tehdä omia mallejaan, pitää varautua kokeiluihin ja iteraatioihin. Myös manuaalin vihjeet reparametrisaatiosta ja vektoroinnista on syytä ottaa vakavasti.
Ajoajat ovat tällä mallilla kohtuullisia, mutta datakin on pieni. On vaikea antaa ylärajaa Stan-mallien datan koolle, koska estimoinnin nopeus riippuu niin paljon mallista. Käytännössä mallit luokkaa 10⁴–10⁶ datapisteelle ovat mahdollisia. Olen itse sovittanut malleja, joissa on satoja tuhansia datapisteitä ja yhtä paljon parametreja.
(Kirjoittaja on päätynyt akateemisten ja muiden kokeilujen jälkeen Reaktorin data science -tiimiin. Luonnoksia kommentoivat ouzor, antagomir, Jarkko ja Jaakko. Pauli antoi datat.)
Alkuperäinen kirjoitus Louhos-blogissa: https://louhos.wordpress.com/2014/01/29/stan-kj/