usdoj, a package for fetching data from the United States (US) Department of Justice (DOJ) API, was released as part of the rOpenGov project. usdoj provides easy access to US DOJ press releases, blog entries, and speeches. Optional parameters allow users to specify the number of results starting from the earliest or latest entries, and whether these results contain keywords. Data is cleaned for analysis and returned in a data frame.
US DOJ press releases, blog posts, and speeches are an official media through which the United States government publicizes front line information about law, enforcement, and crime that may be of interest to members of the public, researchers and analysts, and members of other government branches. They include coverage for divisions such as the Federal Bureau of Investigation (FBI), the Offices of the United States Attorneys (USAO), the National Security Division (NSD), the Civil Division, the Tax Division, the Bureau of Alcohol, Tobacco, Firearms and Explosives (ATF), the Drug Enforcement Administration (DEA), and more. New media are published on a regular basis
usdoj makes this media accessible in an analysis-ready format through three functions that search for and return relevant results: doj_press_releases(), doj_blog_posts(), and doj_speeches(). Data is cleaned and structured before it is returned as a data frame with fields for the body text, date, title, url, the name of the corresponding division, to name just a few.
library(usmap)
library(lubridate)
library(tidyverse)
library(usdoj)
# press_releases <- doj_press_releases(n_results = 100000, search_direction = "DESC")
# write_csv(press_releases, "press_releases_doj_intro.csv")
press_releases <- read_csv("press_releases_doj_intro.csv")
state <- statepop$full
count <- list()
for(state_name in state) {
count <- append(count, sum(str_count(press_releases$name, state_name))) }
df <- data.frame(state = unlist(state), count = unlist(count))
earliest_date <- ymd(min(press_releases$date))
earliest_date <- paste0(month(earliest_date, label = TRUE), " ", day(earliest_date), ", ", year(earliest_date))
latest_date <- ymd(max(press_releases$date))
latest_date <- paste0(month(latest_date, label = TRUE), " ", day(latest_date), ", ", year(latest_date))
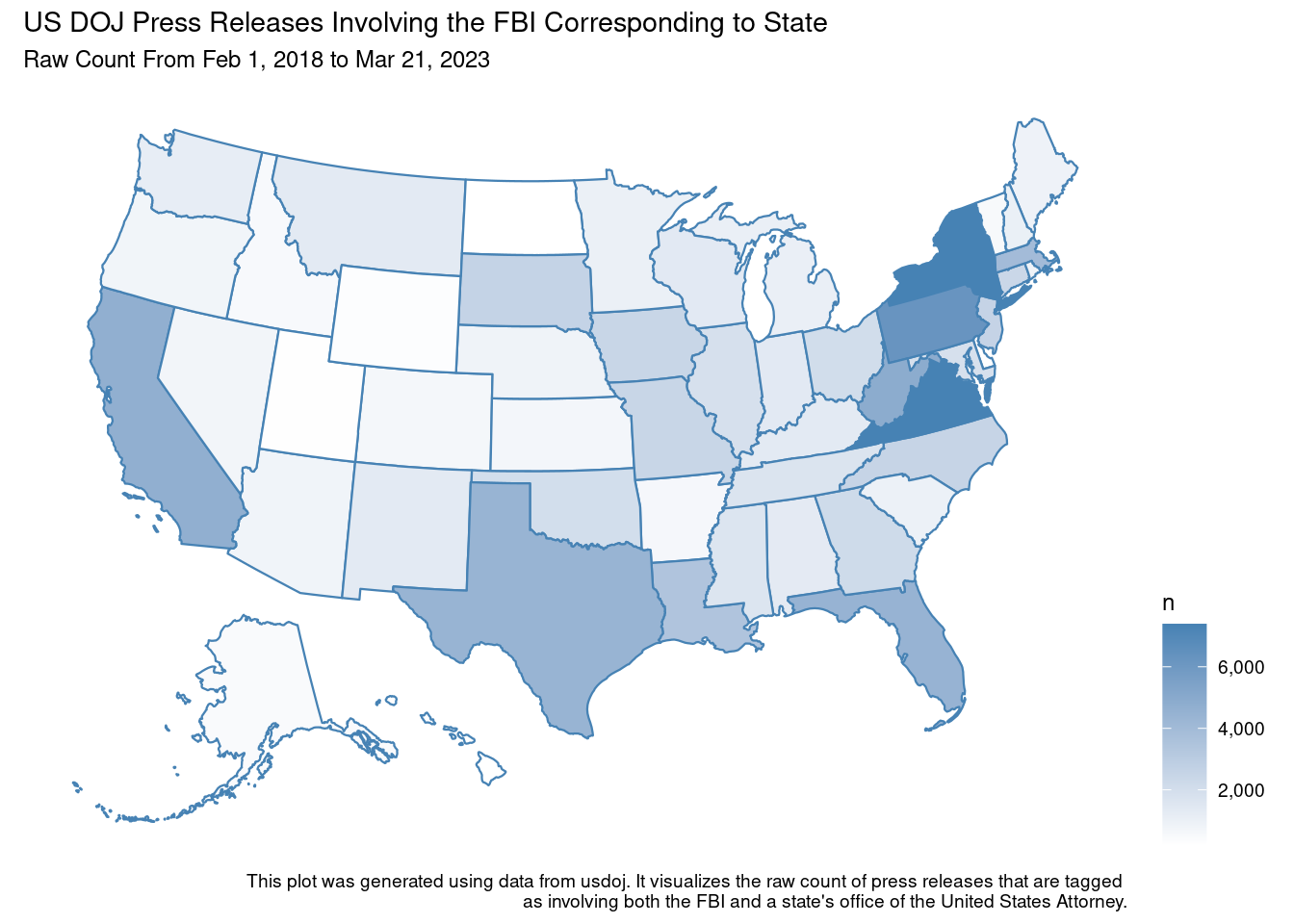
plot_usmap(data = df,
values = "count",
color = "#4682b4") +
scale_fill_continuous(low = "white",
high = "#4682b4",
name = "n",
label = scales::comma) +
theme(legend.position = "right") +
labs(title = "US DOJ Press Releases Involving the FBI Corresponding to State",
subtitle = paste0("Raw Count From ", earliest_date, " to ", latest_date),
caption = "This plot was generated using data from usdoj. It visualizes the raw count of press releases that are tagged
as involving both the FBI and a state's office of the United States Attorney.")
Demonstration: Text Mining United States Department of Justice Open Data
The data returned by usdoj is in a format that can easily undergo additional processing for analysis. The purpose of this section is to show one way of doing this while walking through the steps for performing a TF-IDF (term frequency-inverse document frequency) analysis in order to see which words are characteristic to certain divisions, and not others.
Installing and Loading Libraries
usdoj can be installed from CRAN (using install.packages("usdoj")) or from rOpenGov’s r-universe. For this tutorial we will also use the tidyverse and tidytext libraries.
library(usdoj)
library(usmap)
library(tidyverse)
library(tidytext)
library(lubridate)
We will start by collecting US DOJ press releases with the corresponding function, doj_press_releases(). By default, the most recently published records are returned. Passing search_direction = "ASC" to the function will instead return data starting at the earliest published records. usdoj automatically flattens nested fields. The resulting data frame is easily text mined.
press_releases <- doj_press_releases(n_results = 700)
We will also save the date range present in the data for use in our visualization (later on).
earliest_date <- ymd(min(press_releases$date))
earliest_date <- paste0(month(earliest_date, label = TRUE), " ", day(earliest_date), ", ", year(earliest_date))
latest_date <- ymd(max(press_releases$date))
latest_date <- paste0(month(latest_date, label = TRUE), " ", day(latest_date), ", ", year(latest_date))
write_csv(press_releases, "intro_pt_2.csv")
press_releases <- read_csv("intro_pt_2.csv", show_col_types = FALSE)
A single field may contain multiple values. For example, the field “name” contains the (sometimes multiple) US DOJ divisions related to a press release, as shown by lines 7 and 9. A single press release may relate to USAOs across multiple states or may implicate multiple offices.
head(press_releases$name, 10)
[1] "Office of the Attorney General"
[2] "Civil Rights Division"
[3] "Civil Division"
[4] "Criminal Division"
[5] "Environment and Natural Resources Division"
[6] "Office of the Deputy Attorney General"
[7] "Environment and Natural Resources Division"
[8] "Tax Division"
[9] "Criminal Division"
[10] "Tax Division"
In this demonstration we will process the text body, transforming the dense blocks of natural language text into a structure that is more easily quantifiable.
tail(press_releases$body, 2)
For this demonstration, we will just compare the words relating to United States Attorney Offices (USAOs) across different states. We will do this by removing mentions of the other divisions from the “name” field and filtering for just press releases that contain USAO as a division.
state_names <- paste(statepop$full, collapse = "|USAO - ")
press_releases$name <- str_extract(press_releases$name, paste0("USAO - ", state_names))
usao_press_releases <- press_releases %>%
filter(str_detect(name, "USAO"))
The following code tokenizes the body text, a process through which dense paragraphs are separated into one-word-per-row.
tokenized_press_releases <- usao_press_releases %>%
select(body, name) %>%
unnest_tokens(word, body)
For this demonstration we will remove digits because they occur frequently in the data set and, for our purposes, they don’t reveal much meaningful information.
cleaned_tokenized_press_releases <- tokenized_press_releases %>%
slice(which(!str_detect(word, "[[:digit:]]")))
In preparation of performing a TF-IDF analysis, we will count the number of times a word appears in each unique “name” grouping. In other words, if the same word appears in “Civil Division” and “Antitrust Division,” then the count will be “one” for each division (as opposed to “two,” reflecting the overall count). To remove typos and other such errors, we will also remove words that have been stated less than 5 times.
counted_tokenized_press_releases <- cleaned_tokenized_press_releases %>%
count(name, word) %>%
filter(n > 5)
head(counted_tokenized_press_releases)
We will now gather the overall word count per “name” grouping and use bind_tf_idf() to see which words are characteristic of one grouping and not the others.
total_words_per_group <- counted_tokenized_press_releases %>%
group_by(name) %>%
summarize(total = sum(n)) %>%
ungroup()
counts_and_totals <- left_join(counted_tokenized_press_releases, total_words_per_group)
usao_press_releases_tf_idf <- counts_and_totals %>%
bind_tf_idf(word, name, n)
We can now visualize which words are characteristic of one “name” grouping and not another. In the following code we take the top 10 words per name grouping and plot them based on their TF-IDF scores.
top_usao_press_releases <- usao_press_releases_tf_idf %>%
group_by(name) %>%
arrange(desc(tf_idf)) %>%
slice(1:10) %>%
ungroup()
ggplot(top_usao_press_releases,
aes(tf_idf, reorder_within(word, tf_idf, name),
fill = name)) +
labs(title = "TF-IDF Scores By USAO Grouping",
subtitle = paste0("US DOJ Press Releases From ", earliest_date, " to ", latest_date)) +
geom_col(show.legend = FALSE) +
facet_wrap(~name, ncol = 2, scales = "free") +
scale_y_reordered() +
labs(x = "tf-idf", y = NULL)