Hesari ja Kansan muisti julkaisivat keväällä mielenkiintoisen kansanedustajien puheista koostetun datasetin. Datan perusteella syntyikin useita mielenkiintoisia visualisointeja osana HS Open 4 -tapahtumaa. Näin laaja aineisto tarjoaa myös mainion mahdollisuuden kokeilla aihepiirianalyysiä (engl. topic model). Se on tilastollinen koneoppimismenetelmä, jolla laajoista tekstidokumenttikokoelmista voidaan etsiä toistuvia aihepiirejä (topic). Esimerkiksi kansanedustajien puheista voidaan automaattisesti tunnistaa eduskunnassa käsiteltyjä aiheita, ja mitata edustajien verbaalista aktiivisuutta kunkin aiheen tiimoilta.
Aihepiirianalyysissä kukin aihepiiri koostuu joukosta sanoja, jotka esiintyvät usein aihepiirin keskusteluissa. Vastaavasti kukin dokumentti, tässä tapauksessa tietyn kansanedustajan puheet, sisältää joukon aihepiirejä. Esimerkiksi viisi todennäköisintä sanaa aihepiirille 7 ovat koulutus, ammattikorkeakoulu, aloituspaikka, opiskelija, ja esillä, ja aihepiirille 19:lle puolustusvoima, suomi, sopimus, jalkaväkimiina, ja Afganistan. Näiden sanojen perusteella esimerkkiaihepiirit on helppo nimetä koulutusta ja maanpuolustusta käsitteleviksi. On tärkeää huomata, että kukin sana voi esiintyä useammassa kuin yhdessä aihepiirissä, esimerkiksi sanaa suomi käytetään kansanedustajien puheissa monessa yhteydessä.
Aihepiirianalyysin tulokset voisi esittää listaamalla annettujen esimerkkien tyyliin kullekin aihepiirille todennäköisimmät sanat ja vastaavasti kullekin kansanedustajalle todennäköisimmät aihepiirit. Erityinen eye diagram -visualisointi tiivistää mallin löytämät yhteydet yhteen kuvaan:
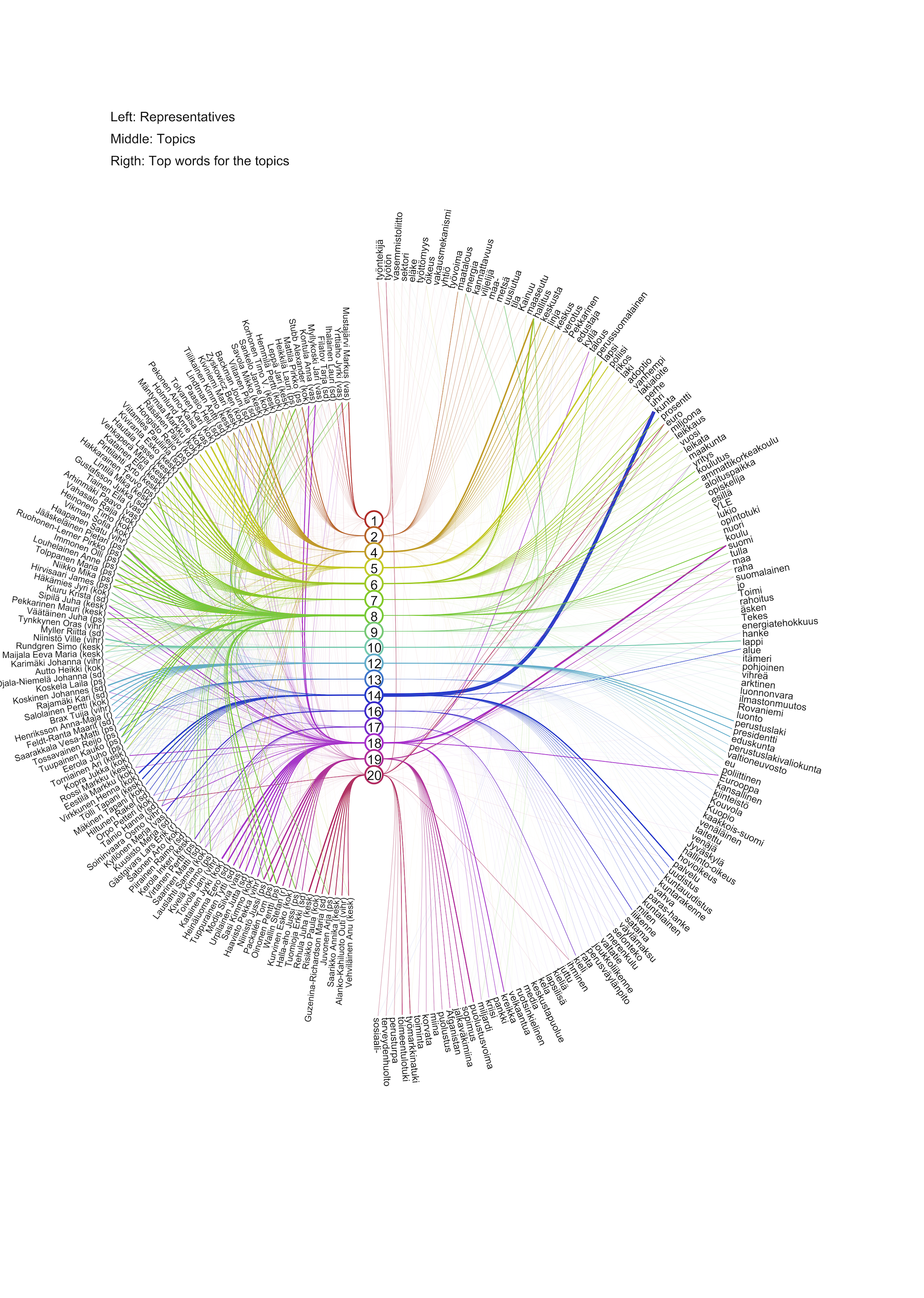
Esimerkkiaineistomme eye diagram-visualisoinnissa (PDF-versio) kansanedustajat ovat vasemmalla, aihepiirit keskellä ja sanat oikealla. Viivojen leveydet kuvaavat mallin määrittämiä todennäköisyyksiä kansanedustajien ja aihepiirien ja vastaavasti aihepiirien ja sanojen välillä. Kunkin aihepiirin yhteydet on esitetty omalla värillään ja lisäksi kuhunkin aihepiiriin liittyvät kansanedustajat ja sanat on tulkinnan helpottamiseksi pyritty listaamaan peräkkäin. Pienen tutustumisen jälkeen visualisoinnista löytyy selkeitä aihepiirejä. Tässä esimerkiksi-visualisointi, jossa on korostettu selvästi eurokriisiin liittyvän aihepiirin yhteydet.
Esimerkki valaisee aihepiirianalyysin tarjoamia mahdollisuuksia tekstidatan analysoinnissa. Tuloksia olisi mahdollista tulkita tarkemminkin puheiden ajankohdan ja puolueen mukaan. Lisäksi vuorovaikutteinen versio eye diagram -visualisoinnista helpottaisi tulkintaa entisestään. Aihepiirianalyysi antaa nopean yleiskuvan eduskunnan ajankohtaisista keskustelunaiheista ja toimijoista.
Teknisiä yksityiskohtia
R-koodit analyysin toistamiseen löytyvät alta sekä Louhos-projektin Takomo-reposta. Visualisointi on toteutettu Processing:lla, ja lisäksi tarjolla on yksinkertainen R-rajapinta.
Hesarin julkaisemassa datasetissä Eduskunnan puheet olikin jo Kansan muistin toimesta muutettu perusmuotoon, mikä on käytännössä edellytyksenä suomenkielisen datan analysoinnissa. Osa mallin löytämistä aihepiireistä on yleisempiä, kuten topic 15 (myös, asia, pitää, sitten ja aika), jota käyttävät suurin osa kansanedustajista. Tällaiset aihepiirit eivät ole erityisen mielenkiintoisia, ja visualisoinnista onkin selvyyden vuoksi poistettu aihepiirit 3, 11, ja 15. Toinen höydyllinen esikäsittelyvaihe tekstidatan analyysissä on erilaisten yleisten sanojen, kuten ja, tai ei poistaminen. Tässä analyysissä poistin joukon ns. sulkusanoja (engl. stop word), mutta enemmänkin vastaavia sanoja voisi poistaa, kuten aihepiiri 15 osoittaa.
Aihepiirianalyysi ajettiin R:n topicmodels-paketilla, mutta R:ssä olisi tarjolla muitakin toteutuksia topic-mallille. Mallin ajaminen vaatii erinäisten parametrien asettamisen, niistä tärkeimpänä aihepiirien määrä. Tässä analyysissä määräksi asetettiin 20 sen kummemmin validoimatta. Lisätietoa aihepiirien määrän oikeaoppisesta validoinnista ja muista parametreista löytyy esimerkiksi topicmodels-paketin oheismateriaalissa. Eye diagram -visualisointikoodi on saatavilla githubissa.
PÄIVITYS 6.1.2013: Blogin R-skriptejä ylläpidetään jatkossa Githubissa. Tämän artikkelin koodit löytyvät täältä.
Alkuperäinen kirjoitus Louhos-blogissa: https://louhos.wordpress.com/2012/08/20/aihepiirianalyysi-kansanedustajien-puheista/